Alchemy is a collection of independent library components that specifically relate to efficient low-level constructs used with embedded and network programming.
The latest version of Embedded Alchemy[^] can be found on GitHub.The most recent entries as well as Alchemy topics to be posted soon:
- Steganography[^]
- Coming Soon: Alchemy: Data View
- Coming Soon: Quad (Copter) of the Damned
I have previously written about code rot (code decay). This post is about decay in a different context. Essentially there are three sets of types in C++ that will decay, lose information. This entry will describe the concept, the circumstances, and in some cases ways to avoid type decay from occurring. This is an important topic for me to cover because the addition of support for arrays in Alchemy would have been much more difficult without knowledge of this concept.
Type Decay
Why do certain types decay? Maybe because they have a short half-life?! I actually do not know the reasoning behind all of the rules. I suspect they exist mostly to help things run much smoother. Type decay is a form of syntactic sugar. This is because the original type, T1, is attempting to be used in a context that does not accept that type. However, it does accept a type T2, that T1 can be converted to.
Generally the circumstances involve attempting to use a type T1, in an expression, as an operand, or initializing an object that expects a type T2. There are other special cases such as a switch statement where T2 is an integral type or when the expression T2 reduces to a bool.
The rules are quite involved. For details on the rules for order of conversion I recommend the page on Implicit Conversions[^] at cppreference.com.
Lvalue transformations
I am only going to delve into the implicit cast scenarios that relate to Lvalue transformations. This may sound redundant, but an Lvalue transformation is applied when an lvalue argument is used in a context where an rvalue is expected. Well, it's a lot more redundant if you substitute T1 for lvalue and T2 for rvalue.
Briefly, an lvalue is a type that can appear on the left hand of an assignment expression. In order for a type to qualify as an lvalue, it must be a non-temporary object or a non-temporary member function. This basically says that a data type with storage will exist when the time comes to write to storage.
An rvalue is just the opposite. It is an expression that identifies a temporary object and is not a value associated with any object. Literal values and function call return values are examples of rvalues, as long as the return type is not a reference.
L-value to R-value
This type of conversion occurs in order to allow expressions to be assign in a series of expressions, or as a result of situations where rvalues are not present. Such as a function that returns a reference to a type.
For this implicit conversion scenario, the lvalue is effectively copy-constructed into a temporary object so that it qualifies as an rvalue type. Other potential conversion adjustments may be made as well such as removing the cv-qualifiers (const and volatile).
This is a fairly benign scenario of type decay, unless your lvalue type has an extremely expensive copy-constructor.
Function to pointer
The second scenario is another simple case. If a the lvalue is a function-type, not the actual expression of a function call, just the type, it can be implicitly converted to a pointer. This explains why you can assign a function to an expression that requires a function pointer, yet you are not required to use the & to take the address of the function. Although if you do, you will still get the same results, because the implicit conversion no longer applies to the pointer to a function.
Array to pointer conversion
This is the case that I needed to understand in order to successfully add support for arrays to Alchemy. If an lvalue is an array-type T with a rank of N, the lvalue can be implicitly converted to a pointer to T. This pointer refers to the first element in the original array.
I have been using C++ for almost two decades, and I am surprised that I did not discover this before now. Take a look at the following code. What will it print when compiled and run on a 64-bit system?
C++
void decaying(char value[24]) | |
{ | |
std::cout << "value contains " << sizeof (value) << "bytes\n"; | |
} |
Hopefully you surmised that since T1 is open to the implicit conversion to a pointer to a char, the sizeof call will return the size of a 64-bit pointer. Therefore, this string would be printed "T1 contains 8 bytes".
I discovered this when I was building my Alchemy unit-tests to verify that the size of an array data type was properly calculated from a TypeList definition. It only took a little bit of research for me to discover there is actually a special declaratory that can be used to force the compiler to prevent the implicit conversion of the array. Depending on your compiler and settings, you may get a helpful warning when this conversion is applied.
This declarator is called a noptr-declarator. To invoke this declaratory, use a *, & or && in front of the name of the array. Parenthesis will also need to be placed around the operators and the name of the array. The resulting definition becomes a pointer or a reference to an array of type T, rather than simply a pointer to T. The sample below shows the declaration that is required to avoid the implicit cast.
C++
void preserving(char (&value)[24]) | |
{ | |
std::cout << "value contains " << sizeof (value) << "bytes\n"; | |
} |
Here is a brief example to demonstrate the syntax and differences:
C++
int main(int argc, char* argv[]) | |
{ | |
char input[24]; | |
| |
std::cout << "input contains " << sizeof(input) << " bytes\n"; | |
| |
decaying(input); | |
preserving(input); | |
| |
return 0; | |
} |
Output:
main: input contains 24 bytes decaying: value contains 8 bytes preserving: value contains 24 bytes
This simple modification allowed me to preserve the type information that I needed to properly process array data types in Alchemy. In my next entry, I will demonstrate how template specialization can be used to dismantle the array to determine the type and the rank (number of elements) that are part of its definition.
std::decay< T >
This function is part of the C++ Standard Library starting with C++ 14. It can be used to programmatically perform the implicit casts of type decay on a type. This function will also remove any cv-qualifiers (const and volatile). Basically, the original type T will be stripped down to its basic type.
I haven't had a need to use this function in Alchemy. However, it is helpful to know about these utility functions and what is possible if I ever find the need to extract only the type.
Summary
The C++ compiler is a very powerful tool. Sometimes it attempts to coerce types and data into similar forms in order to compile a program. In most cases this is a very welcome feature because it allows for much simpler expressions and reduces clutter. However, there are some cases where the implicit casts can cause grief.
I stumbled upon the array to pointer type decay conversion during my development of Alchemy. Fortunately, there are ways for me to avoid this automatic conversion from occurring and I was able to work through this issue. Subtleties like this rarely appear during development. It is definitely nice to be aware that these behaviors exist, so you can determine how to work around them if you ever encounter one.
A continuation of a series of blog entries that documents the design and implementation process of a library. The library is called, Network Alchemy[^]. Alchemy performs low-level data serialization with compile-time reflection. It is written in C++ using template meta-programming.
After I had completed my initial targetted set of features for Alchemy, demonstrated the library to my colleagues, and received the initial round of feedback, I was ready to correct some mistakes. The completion of nested structures in my API was very challenging for many reasons. This required each object to know entirely too much about the other constructs in the system. I was very motivated to find an elegant and effective solution because the next feature I decided to tackle would be very challenging, support for arrays. I turned to Proxies to solve this problem.
Proxy Design Pattern
You can learn more about the Proxy design pattern in the Gang of Four pattern book. This design pattern also referred to as the Surrogate. There are many types of proxies listed, such as Remote Proxy, Virtual Proxy, Protection Proxy and Smart Reference. To be technical, my use of proxies most closely relates to both the Virtual and Protection Proxy. However, in order to make all of the pieces fit together as smoothly as they do now, it also resembles the Adapter pattern, with a bit of Strategy, or as we refer to them in C++, policies.
Consequences
The benefits that were realized by the mixed use of these patterns are summarized below:
The adapter qualities of the solution helped eliminate the slight incompatibilities between the different types. This allowed the different data types to remain completely orthogonal and the code to be written in a very generic fashion.
The Proxy provided a natural location to hide the extra type definitions that were required to properly maintain the variety of Datum that is supported.
Policies are used to control the behavior and implementation selected to process byte-order management, storage access rules, and memory allocation.
Restructuring
I didn't actually arrive at the use of the proxy by judicious analysis, nor by randomly selecting a design pattern to "See if I can make this one fit". Before I moved on to arrays, I wanted to restructure the definition MACROS that were required to define a Hg message and its sub-fields. As I mentioned in the previous post, different MACROs were required by the nested type, based on its use.
Also, BitLists required their own MACRO inside of the nested field declarations because of their slight difference in structure than a regular data field. In essence, the BitList contains data like any other Datum, however, I used a virtual proxy in my original implementation to allow the sub-fields to be accessed with natural member data syntax.
I continued to rework the structure of the objects, relying on my strong set of unit-tests to refactor the library until I arrived at a solution that was clean and robust. Each iterative refactor cycle brought me closer and closer to a solution where every data type was held in a proxy.
Here is a sample of what a message definition looked like before the restructured definitions:
C++
typedef TypeArray | |
< | |
uint8_t, | |
uint16_t, | |
mixed_bits, | |
uint32_t, | |
int16_t | |
> nested_format_t; | |
// A nested data-type can not behave as a top-level message. | |
// A separate definition is required. | |
HG_BEGIN_NESTED_FORMAT(nested_format_t) | |
HG_MSG_FIELD(0,uint8_t , zero) | |
HG_MSG_FIELD(1,uint16_t , one) | |
HG_MSG_FIELD(2,mixed_bits, two) | |
HG_MSG_FIELD(3,uint32_t , three) | |
HG_MSG_FIELD(4,int16_t , four) | |
HG_END_NESTED_FORMAT | |
| |
// A sample message declaration | |
HG_BEGIN_PAYLOAD(Hg::base_format_t) | |
HG_MSG_FIELD(0, uint32_t, word_0) | |
HG_MSG_FIELD(1, Hg::nested_format_t, nested) | |
HG_END_PAYLOAD |
Here are the results of my simplified definitions:
C++
// The TypeList definition is the same | |
HG_BEGIN_FORMAT(nested_format_t) | |
HG_DATUM(0,uint8_t , zero) | |
HG_DATUM(1,uint16_t , one) | |
HG_DATUM(2,mixed_bits, two) | |
HG_DATUM(3,uint32_t , three) | |
HG_DATUM(4,int16_t , four) | |
HG_END_FORMAT | |
// The nested formats are now compatible | |
HG_BEGIN_FORMAT(Hg::base_format_t) | |
HG_DATUM(0, uint32_t, word_0) | |
HG_DATUM(1, Hg::nested_format_t, nested) | |
HG_END_FORMAT |
Finally, I thought it was idiotic that the index had to be explicitly stated for each field. Therefore I created a way to auto-count with MACROs using template specialization, and I was able to eliminate the need to specify the index for each Datum.
Unfortunately, the nature of my particular use of the auto-count MACRO is not compatible with the standard. This is because I need the template specializations to be defined within a class. The standard prohibits this and requires template specializations to be defined at a namespace scope.
I was able to port the entire solution in Visual Studio because its compiler is very lax on this restriction. None-the-less, I was still able to use my simplified MACROs because I adapted the non-standard __COUNTER__ MACRO to achieve my goal. I would have used __COUNTER__ in the first place, but I was trying to create a 100% portable solution.
I will most likely revisit this again in the future in search of another way. In the mean time, here is what the final Hg message definition looked like:
C++
HG_BEGIN_FORMAT(nested_format_t) | |
HG_DATUM(uint8_t , zero) | |
HG_DATUM(uint16_t , one) | |
HG_DATUM(mixed_bits, two) | |
HG_DATUM(uint32_t , three) | |
HG_DATUM(int16_t , four) | |
HG_END_FORMAT |
Application
There is only one difference between how I integrated the BitList proxy from my original implementation to the implementation that is currently used. I inverted the order of inheritance. In my original version the Datum was the top-level object, and was able to adjust which proxy or other object type was the base with SFINAE[^].
The new implementation starts with a Datum for all object types, and DataProxy is the derived class that hides, adapts and optimizes all of the specialized behavior of the different data types supported in Alchemy. Therefore, the message collection object stores a set of DataProxy objects with a single Datum type that behaves as the base class for all types. This is exactly the type of clean solution that I was searching for.
Basic Data Proxy
The goal for all of the DataProxy objects, is to provide an implied interface to access the underlying storage for the data type. The implicit interfaces allow static polymorphism to be used to associate each type of data to be cleanly associated with a Datum object.
The DataProxy objects provide constructors, assignment operators, and value conversion operators to the underlying value_type value as well as a reference to the value_type instance. After methods to gain access to the actual data, the DataProxy also provides a set of typedefs that allow the generic algorithms in Alchemy and the C++ Standard Library to effectively process the objects.
Here is a partial sample of the basic DataProxy objects class declaration, and object typedefs:
C++
template< typename datum_trait, | |
size_t kt_idx, | |
typename format_t | |
> | |
struct DataProxy | |
: public Hg::Datum< kt_idx, format_t > | |
{ | |
typedef Hg::Datum < kt_idx, | |
format_t | |
> datum_type; | |
typedef typename | |
datum_type::value_type value_type; | |
typedef datum_type& reference; | |
// ... |
Nested Data Proxy
The adjustments that I made during my refactor went incredibly well. It went so well, in fact, that not only could I use any nested data type at both the top-level and as a sub-field, I was also able to use the same generic DataProxy that all of the fundamental data types use. There was no need for further specialization.
Deduce Proxy Type
I gained a new sense of confidence when I recognized this. Furthermore, the only trouble I would occasionally run into was how to keep the internal implementation clean and maintainable. I then started to collect all of the messy compile-time type selection into separate templates that I named DeduceX.
Given a set of inputs, the template would execute std::conditional statements, and define a single public typedef type that I would use in my final definition. Here is the type-deduction object that is used to declare the correct DataProxy type. This object determines the correct type by calling another type-deduction object to determine the type-trait that best defines the current data type.
C++
template< size_t IdxT, | |
typename FormatT | |
> | |
struct DeduceProxyType | |
{ | |
// Deduce the traits from the value_type | |
// in order to select the most | |
// appropriate Proxy handler for value | |
// management. | |
typedef typename | |
DeduceTypeAtTrait < IdxT, | |
FormatT | |
>::type selected_type; | |
// The selected DataProxy type for the | |
// specified input type. | |
typedef DataProxy < selected_type, | |
IdxT, | |
FormatT | |
> type; | |
}; |
Bit-list Proxy
If it were not for the child data fields published by the BitList, this object would also be able to use the basic DataProxy. The BitList differs from a nested data type in that the BitList does not process each of its child elements during data process actions. The data is stored internally in the same format it will be serialized. The nested type doesn't process its own data, rather it defers and recursively commands its children to process their data.
The functionality required of the BitListProxy is very minimal. A default constructor, copy constructor, assignment operator, and value conversion operator are required to provide access to the actual storage data. A portion of the BitListProxy is listed below:
C++
template< size_t kt_idx, | |
typename format_t | |
> | |
struct DataProxy< packed_trait, | |
kt_idx, | |
format_t> | |
: public Datum<kt_idx , format_t> | |
{ | |
// ... | |
DataProxy(DataProxy& proxy) | |
: datum_type(proxy) | |
{ | |
this->set(proxy.get()); | |
} | |
operator reference() | |
{ | |
return *static_cast< datum_type* >(this); | |
} | |
operator value_type() | |
{ | |
return | |
static_cast<datum_type*>(this)-> | |
operator value_type(); | |
} |
Array / Vector Proxy
I have not yet introduced the array and vector types in how they relate to Alchemy. However, there is not much discussion required to describe their implementations of the DataProxy object. Besides, the sample code is probably starting to look a bit redundant by now. The complication created by these two types are the many new ways that data can be accessed within the data structure itself.
I wanted the syntax to remain as similar as possible to the versions of these containers in the C++ Standard Library. Therefore, in addition to the specialized constructors and value operators, I mimicked the corresponding interfaces for each container type.
Implementations for the subscript operator was provided for both classes as well as other accessor functions such as at, size, front, back, begin, and end of all forms. Using iterators through these proxy objects is transparent and just as efficient as the container themselves.
Since the vector manages dynamically allocated memory, a few more functions are required to handle the allocation and deallocation operations. These additional functions were added to the Hg::vector's DataProxy interface: clear, capacity, reserve, resize, erase, push_back and pop_back.
Results
I was very pleased with the results. For a while I felt like I was fumbling with a 3-D puzzle or some brain-teaser. I could visualize the result I wanted, and how the pieces should fit together. It just remained a challenge to find the right combination of definitions for the gears to interlock for this data processing contraption.
As I moved forward and added the implementations for arrays and vectors, I was able to pass a consistent definition to most of the algorithms, and allow the type-trait associated with the DataProxy object to properly dispatch my calls to the most appropriate implementation. Generally only two parameterized types were required for most of the functions, the TypeList that describes the format, and the Index of the data field within the TypeList.
One of the most valuable things that I took away from this development exercise is an improved understanding of generic programming principles. I also gained a better understanding of how apply functional programming principles such as currying and lazy evaluation of data.
Summary
Overall, the modification to Alchemy to separate the different supported data types with proxies has been the most valuable effort spent on this library. The difference between the proxy objects interfaces are somewhat radical. However, they have worked very well at providing the proper abstraction for adding additional features for the expanding set of the data types supported by Alchemy.
A continuation of a series of blog entries that documents the design and implementation process of a library. The library is called, Network Alchemy[^]. Alchemy performs low-level data serialization with compile-time reflection. It is written in C++ using template meta-programming.
I am almost done describing the first set of features that I was targeting when I set out to create Alchemy. The only remaining feature to be documented is the ability to have nested types. Basically, structs within structs. This entry describes the approach that I took as well as some of the challenges that I had to conquer in order to create a usable solution.
The Concept
The concept for adding nested field types seemed straight-forward, and it actually is. Recursion with templates and template specialization were the primary tools that I had employed to get as far as I have up to this point. Creating a form of compile-time reflection allowed me to iterate over all fo the fields of a top-level structure. The elegance of the solution was to simply reuse the existing processing on a second-layer structure.
This code is rotting from the inside
I was able to get the basic recursive calls into place rather quickly. However, some of my design decisions caused a great deal of resistance to some of the new changes. One of the challenges was caused by the difference in parameterized-type baggage that each type of data element required. This raised some red flags for me because there were only three datatypes, fundamental, bit-lists and nested structs.
The other issue stemmed from my original approach to memory management. I had envisioned the entire message to be a data-structure that handled memory management and allowed the user to concentrate on the data fields. The data-fields would be serialized as they were accessed, therefore the buffer would always be ready to send off at a moments notice.
The trouble arose because I didn’t want the messages to always be initialized. There are plenty of temporary copies that are created, and performance would have taken an enormous hit if buffers were allocated and immediately destroyed without ever being used. As I was saying, the trouble arose because there were still plenty of times that I had to have the buffers initialized with the proper data.
Templates are supposed to reduce the amount of code that a developer must create and maintain, not multiply it. These are observations that I kept in mind for any possible future revisions.
Fighting the internal structure
In order to initialize the buffers, I found myself creating numerous template specializations to handle each type of data, especially the nested structure. Furthermore, these specializations were located deep inside of the Datum object, which was supposed to be a very generic adapter for all of the data types.
The conundrum I faced, was an internal data field that was stored within each Datum. However, when I would encounter a nested data-type, I didn’t need to create any internal data, because the nested structure held a collection of its own Datum objects. These Datum objects already had their own data. I needed to find a way to avoid the creation of redundant data when I encountered nested fields.
On Shadow Buffers
For the temporary messages, there were never going to have memory allocated for them, I usually needed a way to pass data. So in each Datum, a value_type variable was defined to act as temporary storage. These shadow buffers exist in the current form of Alchemy as well. Albeit a bit refined for efficiency and convenience.
When a message did not have an allocated buffer, and all of the value data was stored in these shadow buffers, scenarios would occur where the data would not be properly flushed to the new object once memory was allocated.
Abstracting the aberration
To combat the ever-growing need for more specializations, which I was also dispatching by hand, I reached for a natural tool to solve this, more template specializations. Actually, I created some adapter classes that encapsulated the type information that I needed, including the data type required for the shadow buffer. I then used the type defined by the user to specialize each data type and allow for the correct functions to be called with tag-dispatching.
Let me explain.
Static vs. Dynamic Polymorphism
When using template heavy solutions, you learn to take advantage of static polymorphism. This is a type of polymorphism that takes advantage of implicit declarations defined within an object. Contrast this with dynamic polymorphism, public inheritance, where the interface declarations must be explicit. There is a direct relationship explicitly defined when inheritance is used.
The implied relationship that is employed with static polymorphism occurs simply because we expect a field named ‘X’ or a function named ‘Y’. When the code is compiled, the template is instantiated, and as long as the implied resource is present, our code will compile. The polymorphism them becomes fixed, or static.
If you have ever wondered why there are so many typedefs defined within the STL containers, value_type, pointer, const_pointer, key_type, size_type and so on. It is because the algorithms used through-out the implementation are using static polymorphism to make the containers interchangeable, as well as the different functions used to implement the basic functionality.
When you have a consistent type-convention to build upon, you are then able to create objects with orthogonal relationships that can still naturally interact with one and other.
Static Polymorphism in use
I created a FieldType struct to abstraction to define the data type I required for each type of Datum that is declared within a Hg message structure.
C++
template< typename FieldT > | |
struct field_data_t | |
{ | |
// The matching data type for the index. | |
// The default implementation uses | |
// the same type as the index type. | |
typedef FieldT value_type; | |
}; |
Notice there are only declarations in this structure. There are no member variable definitions. This is the first part of my abstraction. This next structure has a default template implementation, and each nested definition gets its own specialization:
C++
template< typename FieldT, | |
size_t kt_offset = 0 | |
> | |
struct FieldTypes | |
{ | |
// The type at the index of the | |
// parent type container. | |
typedef FieldT index_type; | |
| |
// The specified value type for | |
// the current Datum. | |
typedef typename | |
field_data_t< index_type >::value_type | |
value_type; | |
value_type m_shadow_data; | |
}; |
This struct definition allows me to map the original type extracted from the defined TypeList, and statically map it to replacement type that is best suited for the situation. The fundamental types simply map to themselves. On the other hand, the nested types map to a specialization similar to the definition below. You will notice that a reference to the value_type is defined in this specialization as opposed to an actual data member like the default template. This is how I was able to overcome the duplication of resources
The ‘F’ in the definition below is actually extracted from a MACRO that generates this specialization for each nested field. ‘F’ represents the nested format type.
C++
template< typename storage_type, | |
size_t kt_offset | |
> | |
struct field_types < F, storage_type,kt_offset > | |
: F##_payload< storage_type, kt_offset > | |
{ | |
typedef F index_type; | |
typedef F##_payload < storage_type, kt_offset > value_type; | |
| |
field_types() | |
: m_shadow_data(This()) | |
{ } | |
| |
value_type& This() | |
{ return *this; } | |
| |
value_type & m_shadow_data; | |
}; |
It is important to note that defining references inside of classes or structs is perfectly legal and can provide value. However, these references do come with risks. The references must be initialized in the constructor, which implies you know where you want to point them towards. Also, you most likely will need to create a copy constructor and an assignment operator to ensure that you point your new object instances to the correct reference.
Finally, here is a convenience template that I created to simplify the definitions that I had to use when defining the Datum objects. This struct encapsulates all of the definitions that I require for every field. When I finally arrived at this solution, things started to fall into place because I only needed to know the TypeList, Index, and relative offset for the field in the final buffer.
I have been able to refine this declaration even further, the most current version of Alchemy no longer needs the kt_offset declaration.
C++
template< size_t Idx, | |
typename format_t, | |
size_t kt_offset | |
> | |
struct DefineFieldType | |
{ | |
// The type extracted at the current | |
// index defined in the parent TypeList. | |
typedef typename | |
Hg::TypeAt< Idx, format_t >::type index_type; | |
| |
// The field type definition that maps | |
// a field type with it's value_type. | |
typedef typename | |
detail::FieldTypes< index_type, | |
OffsetOf::value + kt_offset | |
> type; | |
}; |
Other Mis-steps
There are a few issues that were discovered as my API was starting to be put to use. However, the problems that were uncovered were fundamental issues with the original structure and design. Therefore, I would have to take note of these issues and address them at a later time.
Easy to use incorrectly, Difficult to use… at all
The original users of the Hg messages were also confused on how the buffers were intended to be managed and they created some clever wrapper classes and typedefs to make sure they always had memory allocated for the message.
When I saw this, I knew that I had failed in my design because the interface was not intuitive, it created surprising behavior, and most of all, I found myself fumbling to explain how it was supposed to work. I was able to add a few utility functions similar to the C++ Standard Libraries std::make_shared< T >, but this only masked the problem. This wasn’t an acceptable fix to the actual problem.
Redundant Declarations
There was one more painful mistake that I discovered during my integration of nested data types. The mechanism that I used to declare a top-level message made them incompatible with becoming a nested field of some other top-level message. In order to achieve this, the user would have had to create a duplicate definition with a different name.
This was by no means a maintainable solution. I did keep telling myself this was a proof-of-concept and I would resolve it once I could demonstrate the entire concept was feasible.
Requiring two different MACROs to be used to declare a top-level message, and a nested field should have been a red flag to me that I was going to run into trouble later on because how I was treating the two fundamentally similar structures differently:
C++
// Top-level message MACRO | |
DECLARE_PAYLOAD_HEADER(F) | |
| |
// A struct intended to be used as | |
// a nested field inside of a payload header. | |
DECLARE_NESTED_HEADER(F) |
Summary
If I had known what I was building from the start, and had put it to use in more realistic situations during test, I may have been able to avoid the trouble that I encountered while adding the ability to support nested structures. The solution really should have been an elegant recursive call to support the next structure on the queue.
I am actually glad it didn’t work out so smoothly though, because I tried many different approaches and learned a bit more each time I tried a technique where it would be most valuable. Every now and then I still find myself struggling to wrap my head around a problem and find a clean solution. In this context, they now come much easier for me.
Oh yeah, and I eventually did reach the elegant recursive nested fields, which you will learn how in my next Alchemy entry describing my use of proxy objects.
Alchemy: BitLists Mk2
CodeProject, C++, maintainability, Alchemy, design, engineering Send feedback »A continuation of a series of blog entries that documents the design and implementation process of a library. The library is called, Network Alchemy[^]. Alchemy performs low-level data serialization with compile-time reflection. It is written in C++ using template meta-programming.
With my first attempt at creating Alchemy, I created an object that emulated the behavior of bit-fields, yet still resulted in a packed-bit format that was ABI compatible for portable wire transfer protocols. You can read about my design and development experiences regarding the first attempt here Alchemy: BitLists Mk1[^].
My first attempt truly was the epitome of Make it work. Because I didn't even know if what I was attempting was possible. After I released it, I quickly received feedback regarding defects, additional feature requests, and even reported problems with it's poor performance. This pass represents the Make it right phase.
Feedback
Feedback is an important aspect for any software development project that has any value, and would like to continue to provide value. Feedback appears in many types of formats including:
- Bug Reports
- Feature Requests
- Usability
- Performance Reports
- Resource Usage
I realized there were limitations with the first implementation of the BitLists in Alchemy. However, I had created a simple proof-of-concept implementation for version 1, and I needed to finish the serialization and reflection features for the library to provide any value at all.
Imagine my surprise when I received the first requests to expand the capabilities of the BitLists from supporting 8 sub-fields to 32. This was already the most expensive structure as far as size in the library, and expanding its bit-field support to 32 quadrupled the size. Therefore, I knew I would have to revisit the design and implementation of this feature rather quickly.
Re-engineering the BitList
My primary concern with the first implementation of BitList was all of the predefined data fields that it contained. For each possible bit-field managed by the BitList, there was an instance of that variable in the object; whether that field was required or not. The primary reason, all of this work is occurring at compile-time. My initial choices appeared to be:
- Predeclare all of the fields up-front
- Create a different implementation for each BitList length
I often mull over projects in my head while I'm driving, walking and during other idle situations. It didn't take long for me to realize that I had already solved this problem of variable field length in other contexts of Alchemy. I solved it using list objects, just like the TypeList.
With the TypeList, I still only had a single implementation that reserves a slot for up to 32 fields. However, the use of code generatng MACROs and default template parameters allowed me to make this solution transparent to the user. My situation with the BitList is slightly different than the TypeList; I did have an idea to account for this difference.
BTW, if you are wondering why a list-based approach did not occur to me earlier, I had originally called this object a BitSet. I changed the name because of this new approach.
The new approach
My new approach would be to create a host, or head, list object that managed all of the external interfaces and details. Internally, I would build up the list one node at a time until the desired number of entries were defined within the BitList itself. The difference between this BitList and the TypeList is the TypeList does not contain any data or variables that can be referenced by the user. The BitList on the other hand, is an object that is fully defined at compile-time and performs real work at run-time.
The final structure is an embedded linked-list. Similar to the TypeList, each node contains a way to reference the next node in the list. This could possibly become a problem that would impede performance for a run-time based solution. However, once the compiler processes this structure, the code will perform as if it is a flattened array.
I estimated the modifications to be relatively benign to all of the objects outside of the new BitList because it was not dependent on any external objects. Moreover, the meta-functions that I created to calculate the type, size, and offsets of the message fields were generic templates that would recognize the new BitList as the previous BitSet.
The implementation
Modifying the code to use this new format was not terribly difficult. I did struggle with the recursive nature of the algorithm to be able to acheive the same results as the original BitSet. The primary issue that I encountered was how to correctly terminate the list. I would end up with one too-many sub-fields, or the bit-count would not be correct.
This is a situation where one can truly experience the value of having a strong collection of unit-tests written for an object. Very few of my tests required any type of adjustment, and I could quickly tell if my refactoring efforts made the system at least as good as it was before, or worse.
Let's take a brief look at the internals of this implementation.
The BitList host
Similar to my first attempt, I created a base class to root the variable to hold the data and basic contruction logic for these fields. This type also helps determine when the end of the list has been reach. However, this class cannot be the sole terminator as I will demonstrate momentarily.
C++
template< typename T, | |
typename FieldsT >; | |
struct BasicBitList | |
: public bitfield_trait | |
{ | |
typedef BitField< 0, 0, value_type >; nil_bits_t; | |
| |
protected: | |
value_type *m_pData; | |
value_type temp_data; | |
| |
// Can only be instantiated by a derived class. | |
BasicBitList() | |
: m_pData(&temp_data) | |
, temp_data(0) | |
{ } | |
| |
BasicBitList(value_type &data_field) | |
: temp_data(0) | |
{ | |
m_pData = &data_field; | |
} | |
}; |
One more thing I would like to point out that never sat well with me, were the two data fields that I defined. The first is a pointer called, m_pData, which actually points to the real storage location for the bit-field data. This pointer is then passed into each bit-field node to allow the nodes to all reference the same piece of data.
The second defined value is called, temp_data, and acts as a place-holder for an uninitialized BitList. This allows the constructor to always assign the field, m_pData, to a valid memory location. It also allows the use of references in the bit-field node objects, which then avoids the need to check for NULL pointers. Still, this part of my implementation always felt like slapping a band-aid on a symptom, rather than solving the actual problem. I am able to eventually remove this band-aid, but not until my third iteration of the BitList.
Let's move from the base class to the top-level host for the BitList, BitFieldList. This first section of logic shows the declaration of the class, common typedefs and constants. This is the class that acts as the head; of the linked-list structure. I am able to make all of the activity resolve itself at compile-time by deriving from a BitFieldNode, rather than declaring the BitFieldNode as an actual data member of this class.
The parameterized type, RootT, accepts the BasicBitList shown previously. This is passed through each BitFieldNode in the linked list until the terminator. This allows each BitFieldNode to have access to the same member data that all of the BitFieldNodes share.
C++
template< typename RootT, | |
typename SeqT> | |
struct BitFieldList | |
: public BitFieldNode< RootT, 0, 0, SeqT > | |
{ | |
typedef typename | |
RootT::value_type value_type; | |
typedef typename | |
BitFieldNode< RootT, 0, 0, SeqT > base_type; | |
| |
// Constants ********************************* | |
static | |
const size_t k_size = sizeof(value_type); |
The only other definitions for this class are the set of constructors that initiate the cascading initialization process that occurs as each derived BitFieldNode is initialized.
C++
// Default constructor | |
BitFieldList() | |
: base_type() | |
{ | |
RootT::m_data = 0; | |
} | |
| |
// Const Value constructor, | |
// Typically used for temporary instances. | |
// This call will use internal memory to store values. | |
BitFieldList(const value_type &data_field) | |
: base_type() | |
{ | |
RootT::value(data_field); | |
} | |
| |
// Value constructor. | |
BitFieldList(value_type &data_field) | |
: base_type(data_field) | |
{ } |
The BitFieldNode
This class is the innovation of the second iteration of the BitList object. Rather than storing a fixed collection of these types in the container object, a compile-time linked-list is created by deriving the current node from the next node in the sequence. This would most likely cause a very inefficient implementation if it were a solution based on dynamic polymorphism. However, I found through analysis of the compiled code that the overall structure is flattened out by the compiler, and becomes as efficient as if they were all declared as peers in the same container.
C++
template< typename RootT, | |
size_t IndexT, | |
size_t OffsetT, | |
typename SeqT> | |
struct BitFieldNode | |
: BitFieldNode< RootT, | |
IndexT+1, | |
OffsetT+Front< SeqT >::value, | |
typename GetTail< SeqT >::type | |
> | |
{ | |
// Typedef ************************************** | |
typedef typename | |
GetTail< SeqT >::type tail_type; | |
| |
typedef typename | |
BitFieldNode < RootT, | |
IndexT+1, | |
OffsetT+Front< SeqT >::value, | |
tail_type | |
> base_type; | |
| |
typedef typename | |
RootT::value_type value_type; |
While the BitFieldNode derives from the next node in the sequence, this instance defines a BitField object to manage the mask and shift operations to operate on the appropriate bits in the common storage data. The BitField object remains unchanged from the version I used in the first BitList implementation. It is also the same version that I have previously written about.
The salient detail to recognize in the constructors, is the base class is first initialized, then the local BitField is initialized. Remember the base type will eventually reach the BasicBitList that houses and initializes the actual storage data for this entire structure. Therefore on the return pass, each BitFieldNode is initialized with valid data starting from the tail node and finishing at the head.
C++
// Default Constructor. | |
BitFieldNode() | |
: base_type() | |
, m_field( RootT::GetFieldAddress(m_field) ) | |
{ | |
m_field.attach((value_type*)&rhs.m_field); | |
} | |
| |
// Value constructor | |
BitFieldNode(value_type &data_field) | |
: base_type(data_field) | |
, m_field(GetFieldAddress< IndexT >(m_field)) | |
{ | |
// assigns the reference of data_field | |
// to the data member, m_data. | |
m_field.attach(&data_field); | |
} | |
| |
private: | |
BitField< OffsetT, | |
Front< SeqT >;::value, | |
value_type > &m_field; | |
}; |
The BitFieldNode Terminator
At the end of the set of nodes in the linked-list, is a specialization of the BitFieldNode that derives from the passed in BasicBitList rather than the next node in the chain. I cannot recall the exact troubles that I ran into trying to find the correct set of definitions to properly terminate this list. I do remember that I continued to switch back-and-forth between having an incorrect number of sub-nodes in the list and an incorrect offset for each field.
The code below is the final correct solution at which I arrived. The first block contains the declaration and the constructors.
C++
template< typename RootT, | |
size_t IndexT, | |
size_t OffsetT | |
> | |
struct BitFieldNode< RootT, IndexT, OffsetT, MT> | |
: public RootT | |
{ | |
// Typedefs ******************************* | |
typedef typename | |
RootT::value_type value_type; | |
| |
BitFieldNode(const BitFieldNode &rhs) | |
: RootT(rhs) | |
{ } | |
| |
BitFieldNode(value_type &data_field) | |
: RootT(data_field) | |
{ } |
The function below is something that I carried over from the first implementation as well. It allows internal references to the actual BitField objects to be queried by index. The basic mechanism that allows the compile-time reflection to occur over this type.
C++
// A parameterized method that allows the | |
// BitList heirarchy to pragmatically access | |
// the different bit-fields defined in the list | |
// without knowledge of the name of the field. | |
template< size_t Idx, | |
typename field_t > | |
field_t& GetFieldAddress(const field_t&) | |
{ | |
typedef FieldIndex< Idx, RootT, field_t::k_size> field_index_t; | |
| |
// Calls a template member function "GetField" | |
// found in the base class "RootT". | |
// | |
// The static_cast from this to a type "RootT" | |
// is required to give a hint to the compiler where | |
// to look for the "GetField" function. | |
return | |
static_cast< RootT* >(this)->template | |
GetField< field_index_t >(field_t()); | |
} |
The results
Overall I was pleased with this solution, especially compared to my first-pass attempt. This version felt more like a Make it Right type of solution, rather than the starting phase of Make it Work. A few portions of the implementation still didn't sit right with me. For example, an extra dead-weight temporary to ensure that I never dereferenced a NULL pointer.
There is one other source of pain that I experienced with this implementation. This is a result of the deep-derivation that I used to create the compile-time linked list. When I was working through the defects and creating new tests, I spent a fair amount of time in the debugger inspecting the contents of BitList variables and the data found in each node. Unfortunately, this data structure was not very convenient to troubleshoot.
Here are two snapshots of what the following BitList definition looks like when expanded in the Visual Studio debugger:
C++
HG_BEGIN_BITLIST (uint32_t, mixed_set) | |
HG_BIT_FIELD (0, first, 5) | |
HG_BIT_FIELD (1, second, 4) | |
HG_BIT_FIELD (2, third, 3) | |
HG_BIT_FIELD (3, fourth, 2) | |
HG_BIT_FIELD (4, fifth, 1) | |
HG_BIT_FIELD (5, sixth, 16) | |
HG_BIT_FIELD (6, seventh, 1) | |
HG_END_BITLIST |
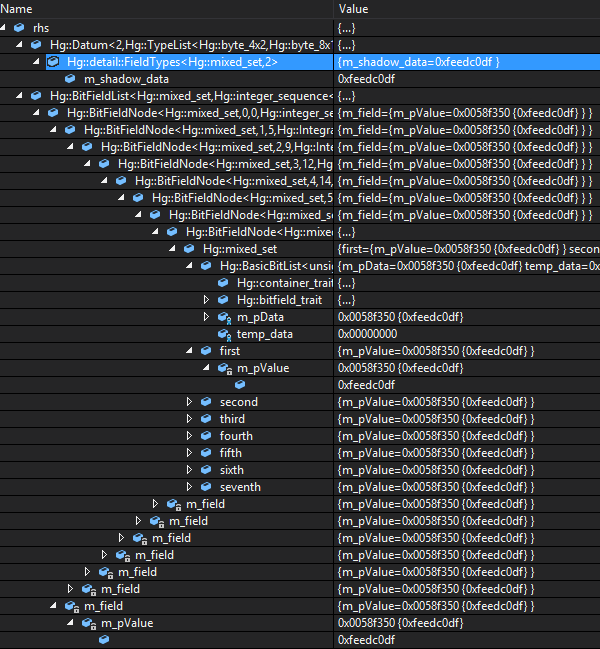
It is easy to see that the value stored in the entire BitList is 0xfeedcodf. However, that is also the value displayed when the bit-fields are expanded. Therefore the debug data viewer provides much less value than I had hoped it would.
This view is an expanded view of just the type names for each field in the derived BitFieldNode chain.
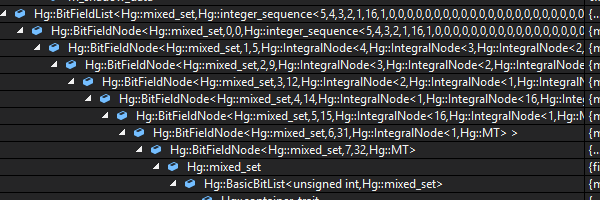
Needless to say this irritated me enough that I eventually created some custom Visual Studio visualizers that I added to Alchemy to correct this inconvenience.
Summary
The usage of the BitList changed from the point-of-view of the final user. However, I was much more satisfied with this solution than the original solution. This solution expands gracefully to any length the user defines (within reason). The amount of space required for each field is reduced to only require space if a BitFieldNode is defined. Therefore, only as much space is allocated as is required for the data structure.
Unfortunately, this data type still remains the most expensive data type that is supported by Alchemy. One pointer is added for each BitField specified in the BitList. This amounts to 4*32 = 128 bytes on a 32-bit system for a BitList with 32 1-bit flags. This is in addition to the other overhead incurred for each type.
I was pushing off my worries about performance as I was not ready yet to write the benchmark tests. I will admit I was concerned, and as you will soon find out, I discovered some very compelling reasons to make my third attempt at implementing the BitList.
Coupling and Cohesion are two properties that deserve your attention when you design software. These are important because they have a direct effect on how flexible and maintainable your software will be as your software continues to e developed. Will you be able to reuse it? Will you be able to adapt it? Will you need a shoe-horn to force that new feature in the future? These questions are much simpler to answer when you can properly gauge the level of Coupling and Cohesion of your components.

Coupling and Cohesion
The source of the terms Coupling and Cohesion originated from the 1968 National Symposium on Modular Programming by Larry Constantine. A more commonly referenced source is from a later published paper called, Structured Software Design (1974), Larry Constantine, Glenford Myers, and Wayne Stevens. This paper discusses characteristics of “good” programming practices that can reduce maintenance and modification costs for software.
Loose (Low) coupling and High (Tight) cohesion are the desirable properties for components in software. Low coupling allows components to be used independently from other components. High cohesion increases the probability that a component can be reused in more places, by limiting its capabilities to small well-defined tasks. For those of you keeping score at home, high cohesion is the realization of the S, Single Responsibility, in SOLID object-oriented design.

Coupling
A measure of the degree to which a component depends upon other components of the system.
| Given two components X and Y: | ||||
| If X changes |  |
→ |  |
how much code in Y must be changed? |
Low coupling is desired because it allows components to be used and modified independently from one and other.
| The next two rows demonstrate coupling dependencies. | ||||
 |
|
 |
 |
 |
 |
 |
 |
 |
 |
|
Very generic coupling, the most compatible bricks. |
||||
    |
||||

Cohesion
A measure of how strongly related the various functions of a single software component are.
| Given a component W: | ||||
|
How focused is W at fulfilling a single responsibility? | |||
High cohesion is desired because:
- Leads to a simpler minimal class that embodies one concept
- A minimal class is easier to comprehend and use
- Therefore it is more likely that this class will be reused
|
These pieces demonstrate cohesion over a range of interfaces. |
||||||
|
Highest cohesion: |
 |
|
||||
 |
|
|
||||
 |
||||||
 |
|
 |
 |
|||
|
Lowest Cohesion: |
 |
|
 |
|||
Reuse of Code
For decades many great minds have envisioned software development to require much less effort than it requires today. Each new process, concept, language or framework has high hopes to be that solution. For example, consider the number of projects built specifically to make JavaScript more manageable. We want to encapsulate the details and abstract away the complexity to provide a clean interface.
It’s important to set your expectations for what to consider reusable code. Without a clear set of expectations, how will you know when you have achieved your goals. More importantly, how can you formulate a design strategy or a reproducible process to consistently create reusable code.
Not all code is reusable
To further clarify this statement, not all code should be reused.
Why Not?
Because the majority of software that is written is designed to fulfill a very specific purpose. The challenge is to find the balance point between generic reusable building blocks, and a tool or application that meets a need. Generic software components are very valuable, however, they are almost useless by themselves.
What good is a linked-list without a mechanism to populate the data in the list, process the data to perform useful outcomes, and later inspect the data. Another example could be a button control for a GUI that handles the name, display and animations of the button. However, it is the actions that are triggered by the button that are important to the end user.
Good design and practices should be used for all software that you write. However, recognize and differentiate which portions of your application are generic and likely to be reused compared to the code that is very specialized. Both of these are of equal importance.
The value of reusable code
For every statement of code that you write or use, you should ask the question:
Does this add value or risk?
Reusable code only provides value If it:
- Is easy to learn and use
- Requires less work -> time -> money to develop your final target
- Has already been tested and proven to be robust
- Results with a project that is at least as robust as the code that it is built upon
If any one of these qualities is undetermined, you may be adding risk along with any perceived value for the reused code.
Increase the potential for code reuse
Here are some design guidelines that can help increase the potential for your code and components to be reusable:
Easy to use correctly, hard to use incorrectly
If you are fan of Scott Meyers’, Effective C++, you will probably recognize this from Item 18:
“Ideally, if an attempted use of an interface won’t do what the client expects, the code won’t compile; and of the code that does compile, it will do what the client wants”
Good interfaces are easy to use correctly and hard to use incorrectly. The example that is used to demonstrate this concept in Effective C++ uses a calendar date class to illustrate the point. Start with a constructor such as this:
C++
class Date | |
{ | |
public: | |
Date(int month, int day, int year); | |
... | |
}; |
This is a reasonable declaration if you live in the United States, which uses the format month/day/year. However, many other countries prefer the format day/month/year. Other possibilities exist such as the ISO 8601 date order with four-digit years: YYYY-MM-DD (introduced in ISO 2014), which is specifically chosen to be unambiguous.
Another problem with this interface is there are three integer input parameters. Without refering to some form of documentation, it may be impossible to deduce the order of the parameters. These are some of the possibilities for how the interface could be misused:
C++
Date d1(2015, 30, 3); // Non-US date format | |
Date d2(30, 3, 2015); // Listing the day first | |
Date d3(1, 30, 2015); // There's only 28 days in Feb. | |
// On yeah, our months are 0-based. |
One possible approach to solving all of the issues above is to create new types to improve clarity and enforce compile-time correctness.
C++
class Month | |
{ | |
public: | |
static Month Jan() { return Month(1);} | |
static Month Feb() { return Month(2);} | |
... | |
private: | |
explicit Month(int m) { ... } | |
}; |
Declaring the only constructor privately forces the user to use the static member functions to create new instances of a Month object. Similar definitions could be created for the day and year parameters. The improved usage would look like this:
C++
Date d(Month::Feb(), Day(20), Year(2015)); |
To encourage correct use, design interfaces that are consistent and behaviorally compatible.
Use these techniques to help prevent errors:
- Create new types
- Restrict operations on those types
- Constrain object values
- Eliminate client resource management
Create interfaces that are minimal and complete
Strive to create the minimal number of operations in your interface to access the complete behavior of the object. Minimal objects embody one concept at the right level of granularity. Also, minimal interfaces are easier to comprehend, and more likely to be used and reused.
Monolithic classes will generally dilute encapsulation. Instead of doing one thing well, they end up providing many things that are mediocre. It is more difficult to make these objects correct and error-safe because they tackle multiple responsibilities. These types of objects usually result from an attempt to deliver a complete solution for a problem.
Encapsulate - Hide/Protect Information
Encapsulation is one of the most valuable aspects of object-oriented programming. Encapsulation is necessary to create a proper abstract design. The purpose of abstraction is to simplify concepts by hiding the details of the abstraction.
A proper abstraction will handle the dirty details required to achieve a correct and error-free implementation. The hidden details verify the invariants of your object each command and when internal state or data is changed. Abstractions become even more effective when a number of internal variables can be managed, and a reduced set of values are presented through the public interface.
3 made up facts… Eh, but probably true
- Programmers like to get the job done
- Programmers are inventive
- If a programmer finds a way to complete a task, even if it requires them to blatantly ignore the comment below, they will still write to the data; Because it will get the job done (refer to factioid 1)
C++
class HopelesslyCoupledFromTheStart | |
{ | |
public: | |
// This is a very sensitive value, you can read but | |
// do NOT write to this value even to get the job done! | |
double m_calibrationOffset; | |
... | |
}; |
Data Members
Declare all data members private. Private data is teh best means a class can use to protect its invariants now as well as in the future as it adapts to possible changes.
Public data members move the responsibility to maintain and guarantee the invariants from the object to all of the code that accesses the abstraction. Freely providing access to an objects data members effectively negates most of the benefits gained from creating the abstraction.
Metaphorical Thought Experiment
WARNING: Visualize this thought experiment at your own risk.
Next time you are considering creating a public data member, think of the human body as an abstraction of a much more complicated biological organism. One where the designer declared all of the data members public rather than private.
- Your internal organs would now all be external organs ripe for the picking of any black-market human organ peddeler.
- All figures of speech related to the body must be interpretted literally: “What’s on your mind?”
- There will be many more Do-it-yourself doctors.
- Negates the benefits of being declared a
friend. - Couples do not need to worry about tight coupling, however, they will need to worry about becoming tangled.
- Humans in space?! Forget it!
The inferiority of non-private data members
Non-private data members are almost always inferior to even simple pass-through getter/setter methods. These methods provide the flexibility in the future to adapt to change as well as these benefits:
- Verify Invariants
- Lazy Evaluation / Data Caching
- Instrumentation
- Decouple for Future Modifications
Protected data members suffer from the same disadvantages as public data members. The responsibility to maintain the invariants is shared with the unbounded set of objects which includes:
- Every class currently derived from this class
- Every class that will be derived from this class in the future
The one exception is the C-style struct or plain-old data (POD), which is used as a behaviorless aggregate and contains no member functions.
Use the weakest coupling relationship possible
Let’s examine the types of relationships that are possible in C++. The list below is ordered by a measure of coupling, tightest to loosest:
friend-shippublicinheritance- Nonpublic inheritance
- Composition (member variable)
Choose the coupling relationship that provides the weakest level of coupling possible. This will provide more flexibility when something needs to be changed in the future.
Prefer writing non-member non-friend functions
This will improve encapsulation by minimizing dependencies, therefore, reduces coupling. The function implementation cannot be modified to depend on the private member data of the class. It can only be implemented based on what is publically accessible.
This will also break apart monolithic classes. The separable functionality can then be further encapsulated by composition.
Example: std::string contains 103 public member functions, 71 could be non-member non-friend implementations.
Use inheritance to achieve substitutability
Inheritance is a wonderful tool available with object-oriented programming. However, it should not be selected as a way to reuse code. Instead, use inheritance as a way to facilitate polymorphism.(For those of you keeping score at home, this concept is the L, Liskov substitutability principle, in SOLID object-oriented design.)
When you consider inheritance, seriously contemplate the is-a relationship between your objects. Think of is-a as “Can be substituted with…".
Public inheritance facilitates polymorphism, which implies substitutability:
| Original Object | … Can be substituted with: | … Not with: | ||
|
|
|
||
Working with your objects will feel cumbersome if you inherit without substitutability.
Don’t inherit to reuse; inherit to be reused.
From Item 37 in C++ Coding Standards, Herb Sutter and Andrei Alexandrescu
Both composition and private inheritance means is-implemented-in-terms-of.
So which one do you use?
Use composition whenever possible. Choose private inheritance when necessary. It becomes necessary when private or protected access to information is required.
Remember, use the solution that creates the weakest coupling relationship:
| public Inheritance | ||||||||
|
C++
|
||||||||
| Composition | ||||||||
|
C++
|
||||||||
| More Composition | ||||||||
|
C++
|
|
||||||
Don’t underestimate the power of composition
Robust composition is easier to achieve compared to inheritance, especially with cohesive interfaces.
 |
 |
Summary
Minding the concepts of coupling and cohesion can lead to more robust software that avoids fragility and is more maintainable.
- Simple definitions and implementations are easier to comprehend and use
- Simple objects can be reused to create more useful objects with composition
- Only use public inheritance when derived objects can truly be substituted for the base object
- Every solution in a computer program is built upon a collection of much simpler solutions
Legos images, trademarks and copyrights belong to the LEGO Group.
I learned a new term today, bikeshedding. After reading about this term, I reached clarity regarding a number of phenomena that I have experienced as a software developer. This term is an example of Parkinson's law of triviality, which was defined by, Cyril Northcote Parkinson, in one of his books, Parkinson's Law: The Pursuit of Progress (1958).
Parkinson's law of triviality:
The time spent on any item of the agenda will be in inverse proportion to the sum involved.
Parkinson's Law
The law of triviality is actually only a corollary to the broader adage, Parkinson's Law, which I am almost certain that you have heard before:
Parkinson's Law:
Work expands so as to fill the time available for its completion.
This book is a series of cynical essays that satirizes government bureaucracies and their tendency to increase in size over time, until they eventually become irrelevant. Parkinson's law of triviality is an example of a committee's deliberations for the expenses of a nuclear power plant, a bicycle shed and refreshments.
Bikeshedding
Why is it called bikeshedding?
Parkinson dramatizes the committee's discussion, and selected a nuclear reactor because of it's vast difference in complexity and expense compared to the bicycle shed. A nuclear reactor is so complex that the average person cannot completely understand it. Contrast this with the relative simplicity of a bike shed. Anyone can visualize a bike shed, and therefore anyone that want's to contribute will add suggestions to show their participation.
Simpler topics will elicit more discussion and debate. Agreement is hardest to achieve for simpler technical problems or organizational topics that can be argued indefinitely.
The Agenda
Let's return to the dramatization of the committee's discussion. Here are the results for each of the three topics:
- The contract for the reactor with a cost of £10 million passes in two and a half minutes because it is to complex and technical.
- The bicycle shed costs £350 and discussion lasts forty-five minutes as everyone in the committee can grasp the number £350. Also, the shed is simple enough that each member has an opinion regarding the building materials and the possibility of saving £50. They are all pleased with themselves with this item concluded.
- Finally, a discussion regarding £21 for the yearly supply of refreshments takes seventy-five minutes. The conclusion is to as the Secretary to gather more information and they will resolve this issue next meeting.
There is a funny email on The Internet called, Why Should I Care What Color the Bikeshed Is?[^] written by, Poul-Henning Kamp. He prefaces the email with this summary:
The really, really short answer is that you should not. The somewhat longer answer is that just because you are capable of building a bikeshed does not mean you should stop others from building one just because you do not like the color they plan to paint it. This is a metaphor indicating that you need not argue about every little feature just because you know enough to do so. Some people have commented that the amount of noise generated by a change is inversely proportional to the complexity of the change.
Clarity
What sort of clarity did I find? A few months ago I wrote a few entries regarding software design patterns. I briefly mentioned the commonly vilified Singleton and promised to follow up with a more detailed exploration of the Singleton. While collecting my thoughts and determine what I wanted to say about the Singleton, I experienced The Singleton Induced Epiphany[^].
I have always had a hard time understanding why so many developers are quick to criticize this design pattern, and I have heard very few criticisms of any other software design pattern. I reached two conclusions by the end of that post:
- The majority of the arguments against the Singleton are criticisms about the languages used to implement the Singleton. For instance up until recently C++ did not have a construct built into the language to be able to create a portable and thread-safe implementation of the Singleton, and therefore the Singleton is bad.
- The Singleton is the simplest design pattern, and most likely the only design pattern that everyone understands completely. Therefore, it is the only design pattern everyone feels comfortable arguing about.
At the time I was unaware that a very succinct term existed to describe the phenomenon that I observed, and now I know that it is called bikeshedding.
Summary
Now that you know of bikeshedding you should be able to recognize this phenomenon. You can then start to curb the pointless discussions about the minutiae and redirect everyone's time and attention to the more important and technical discussions at hand.
What does one-size fits all mean? I suppose there are two way to answer that question, 1) How well do you want it to fit? 2) What do you mean by 'all'? For example, a clothing manufacturer is content with the percentage of the population that their product will fit, such as a T-shirt, hat or Snuggie. All in this case is just a sub-set of the actual population. It should also be stated that the Snuggie will only fit perfectly and look stylish on the most charismatic of cult leaders.

Next time you read an article about programming best practices, consider if the one-size fits all mentality is used by the author. What is their experience level, programming background, project history, or even industry? These are some of the factors that determine how well their advice can be applied to your situation. Especially, if their article only seems to consider situations similar to theirs.
Perspective
Ultimately, I want to illustrate that it is necessary to understand the context and background used by the author to describe a programming methodology or a set of best practices. I am referring to the process du jour such as SCRUM, XP, Waterfall, 6 Sigma, Crouching Tiger, d20, GURPS or what have you. Assuming that the author has found value in the development process of which they are writing, they have most likely applied it with success in a narrow range of projects compared to what exists.
I am not denigrating anyone's experience. I only assert that it is not possible to create a process that is the best possible practice for every type of development project.
Sometimes when I read an article extolling the virtues of a process such as SCRUM, the concepts that are presented seem very foreign to me. This is in spite of having been a part of SCRUM teams that were both successful and unsuccessful in their goals. In a situation like this I find that I become a bit defensive as I read thinking "There is no way that would!"
That is until I stop and consider the context of the article. Is the author an application developer, web developer, or a rocket surgeon for NASA? When you start to consider the author's perspective and the context for which they are writing, it becomes much easier to identify the value in the concepts they are describing. Only then is it possible to take their lessons learned and try to apply them to your context and situation.
Methodologies such as SCRUM, XP and even Waterfall have provided value and been successfully applied for a variety of teams and development projects. Also realize that these same methodologies have failed miserably for all types of development situations. Why?
Context
I believe there are valuable aspects to all development methodologies. However, many of them are specifically designed for use in a certain context. What works well for a web development team might not directly transfer well to a team that develops products for government contracts. Some tailoring and adaptation will most likely be required to see any of the benefits.
Each step prescribed by the process is presumably added to solve a particular problem that has occurred repeatedly during development. While all software development looks the same from the point-of-view of the programmer in the chair, it is naïve to think that this is true for all stages of development in all contexts where software is developed. Many of the articles that I have read either make this naïve assumption, or do not clearly state the context for which the article is written. I have seen this for both average programmers that want to share their experience and the most respected developers in the industry that speak in terms of absolute best practices.
Everyone is trying to find a way to make their daily chores simpler with more reliable development processes. This is especially true for teams where one must coordinate activities with others. This can lead to a lot of floundering for the majority of the population that is not sure what they need to improve their development processes. They discover a new process, but fail to tailor it to their specific situation and wonder why it feels awkward, or they are not seeing the improvements that they expected.
I suspect this is one reason why we often read of the complaints where teams blindly follow the steps prescribed by a development process and it simply feels like a waste of time. These teams have failed to adapt the process to their particular situation.
Experience Level
Our level of experience affects how we are able absorb apply concepts with respect to a subject. The Dreyfus Model of Skill Acquisition is one model of this concept. Essentially, it describes the progression from a Novice to an Expert. As a person becomes more proficient with a skill, they are capable of moving away from rigid sets of rules and guidelines towards an intuitive grasp of the situation based upon on deep tacit understanding.
Novice
As a Novice, we generally rely on a rigid set of rules or plans to lead us to a successful outcome. A practitioner at this level is not expected to exercise much, if any, discretionary judgment to succeed. This is very similar to most baking cookbooks. The recipes are described in steps, and the quality of baked good often depends on how closely the recipe was followed. Attempting to alter the recipe without understanding the purpose of each ingredient and each step could lead to something that is not edible.
Intermediate Levels
More possibilities become available to a student/practitioner as they gain experience. With a greater collection of skills, they can begin to recognize patterns and differentiate between similar situations that require different solutions. As an example let's consider the differences between making the mix for a batch of muffins vs. cookies. The list of ingredients for chocolate chip cookies looks very similar to muffins. In fact, without careful inspection, all of the recipes in a cook book look similar due to their common layout and format. However, there is an enormous difference between the two types of recipes.
With the understanding of a few concepts in baking beyond beginner level, it is possible to slightly alter existing recipes to create a different consistency. Muffins use the "Muffin Method", which combines all of the dry ingredients in one bowl and the wet ingredients in a second bowl. When the oven has reached it's target temperature, the ingredients from both bowls are combined and briefly stirred, placed in the pan, then finally baked in the oven. The ingredients are not combined until the oven is ready, in part because the muffins use baking powder as one of its leaveners. When the acid in the egg whites is mixed with the dry ingredients the baking powder is activated for a brief period of time and will create air bubbles. Once the batter reaches a high enough temperature the batter will set and lock the bubbles in place creating a fluffy texture.
Basic chocolate chip cookies use the "Creaming Method". This is a step where the butter and sugar are beat together to create billions of tiny air bubbles within the mixture. This combination of ingredients adds structure to the cookies because the sugar holds the air until the cookie mix is set in the oven.
What happens if the "Creaming Method" is not strictly followed? The cookies will still probably turn out, however, they will not have the chewy consistency one would expect of this traditional cookie recipe. If the butter is completely melted you will end up with the thin crispy cookie (hey, maybe that's what you wanted). The chewy consistency is also achieved by the gluten that is created when mixing the flour with the water-based ingredients in the mix. To create a less dense cookie you could change the type of flour to eliminate the gluten.
Expert
Expert bakers will simply "know" a few dozen baking recipes and ingredient ratios off the top of their head and know how altering the ratio of the ingredients is likely to affect the final baked good. From this collection of knowledge they would be able to create a plethora of new recipes to suit the needs of each situation they encounter.
Unfortunately, experts will often know a subject so well that some times they are not able to explain how they know the answer, "they just do." This can be intuition leading them to the answer. They have encountered the problem so many times they recognize the pattern and know the right solution. This can lead to problems for less experienced practitioners learning from an expert. Even with a decent amount of experience we are not always able to see all of the connections to arrive at the expert's conclusion. This is one reason why I dislike the phrase "I will leave this as an exercise for the reader."
A Perfect Fit
Software design patterns are similar to recipes for a software development, though not quite. I would compare them more to different techniques in baking such as the "Muffin Method" and the "Creaming Method". You choose a design pattern based on the problem you are trying to solve. Each design pattern is known for providing a good solution to certain classes of problems.
A particular implementation of the design pattern would be comparable to a recipe. The Singleton design pattern is capable of creating solutions more sophisticated than an object that controls it's own creation and limits itself to a single instance. Just as you adapt software design patterns to fit your needs when you develop a software solution, so should you adapt the development processes that you choose to use in your organization.
One final example to illustrate this point. For decades large corporations have been adopting and incorporating SAP database systems to help optimize the logistics of running their company. When these solutions are bought, they require large multi-million dollar investments to customize these systems for the company. The SAP software is already written. However, custom integration is required to make the system usable and useful to the company.
The software development process that you select should be no different. Yes, all SCRUM processes will look similar when compared between different companies that practice this process. However, I would expect there are subtle details that differ between two companies that successfully manage their projects with SCRUM. I believe these subtle differences could be important enough that if one company were to change to the other companies process they would no longer be as successful, or even worse, they no longer succeed.
Summary
It is important to analyze "best practices" and development processes before adopting them to determine how well they fit your organization. I have worked for a half-dozen companies in my career, and none of them setup their build process exactly the same, even though many of them used the same tools. In order to get a best-fit for development processes and practices I would expect some level of customization to be required to be as effective as possible.
A few weeks ago I wrote an entry on SFINAE[^], and I mentioned enable_if. At that point I had never been able to successfully apply enable_if. I knew this construct was possible because of SFINAE, however, I was letting the differences between SFINAE and template specialization confuse me. I now have a better understanding and wanted to share my findings.
What is it?
As I mentioned before enable_if is a construct that is made possible because of SFINAE. enable_if is a meta-function that can help you conditionally remove functions from the overload resolution performed on the type-traits supplied to the function.
You can find examples of it's usage in the Standard C++ Library within the containers themselves, such as std::vector:
C++
template< class _Iter> | |
typename enable_if< _Is_iterator<_Iter>::value, | |
void>::type | |
assign(_Iter _First, _Iter _Last) | |
{ ... } | |
| |
void | |
assign(size_type _Count, const value_type& _Val) | |
{ ... } |
previous block of code accomplish? The assign call will always exist if you want to specify a count and supply a value that is a value_type. However, the conditional version will only be declared if the parameterized type has a type_trait that evaluates to an iterator-type. This adds flexibility to definition of this function, and allows many different instantiations of this function; as long as the type is an iterator.
Also note that the template definition has a completely different signature than the other non-parameterized version of assign. This is an example of overload resolution. I think it is important to point this out, because I was getting caught up into how it should be used. As I perused the Internet forums, it seems that many others are confused on this point as well.
How it works
Let's continue to look at the std::vector. If the parameterized type is not an iterator type, the enable_if construct will not allow the parameterized type to exist. Because this occurs in the template parameter selection phase, it uses SFINAE to eliminate this function as a candidate to participate in the overloaded selection of assign.
Let's simplify this example even further. Imagine the second version of assign does not exist; the only definition is the parameterized version that uses enable_if. Because it is a template, potentially many instantiations of this function will be produced. However, the use of enable_if ensures that the function will only be generated for types that pass the iterator type-trait test.
This protects the code from attempting to generate the assign function when integers, floats or even user defined object types. Essentially, this usage is a form of concept checking that forces a compiler error if the type is not an iterator. This prevents invalid code with types that appears to compile cleanly from getting a chance to run if it will produce undefined behavior.
Another Example
Previously, when I attempted to use enable_if, I tried to apply it in a way that reduced to this:
C++
class Sample | |
{ | |
public: | |
template< typename = | |
typename std::enable_if< true >::type > | |
int process() | |
{ | |
return 1; | |
} | |
| |
template< typename = | |
typename std::enable_if< false >::type > | |
int process() | |
{ | |
return 0; | |
} | |
}; |
Hopefully something appears wrong to you in the example above. If we eliminate the template declarations, and the function implementations, this is what remains:
C++
//template< typename = | |
// typename std::enable_if< true >::type > | |
int process() | |
// ... | |
| |
//template< typename = | |
// typename std::enable_if< false >::type > | |
int process() | |
// ... | |
| |
// This declaration will always trigger an error for a non-existent type: | |
// std::enable_if< false >::type |
When the compiler processes the object, it may not instantiate every function, however, it does catalog every definition. Even though there is a definition for a false case that should not result in the instantiation of that version, it does not affect the overload resolution of the functions. The enable_if definition needs to contain a type that is dependent on the expression. This line will always be invalid:
Types of Usage
There are four places enable_if can be used:
Function return type
This is a common form. However, it cannot be used with constructors and destructors. Typically one of the input parameters must be dependent on a parameterized type to enable multiple function signatures. Overload resolution cannot occur on the return-type alone.
C++
// Only calculate GCD for | |
// type T that is an integer. | |
template< typename T > | |
typename std::enable_if< std::is_integral< T >::value, T >::type | |
gcd(T lhs, T rhs) | |
{ | |
// ... | |
} |
Function argument
This format looks a little awkward to me. However, it works for all cases except operator overloading.
C++
// Only calculate GCD for | |
// type T that is an integer. | |
template< typename T > | |
T gcd(T lhs, | |
T rhs, | |
typename std::enable_if< std::is_integral< T >::value, T >::type* = 0 | |
) | |
{ | |
// ... | |
} |
Class template parameter
This example is from cppreference.com, and it indicates that static_assert may be a better solution that the class template parameter. Nonetheless, here it is:
C++
// A is enabled via a template parameter | |
template< class T, class Enable = void> | |
class A; // undefined | |
| |
template< class T> | |
class A< T , typename std::enable_if< std ::is_floating_point< T>::value >::type> { | |
}; // note: for this use case, static_assert may be more appropriate | |
| |
// usage: | |
// A< int > a1; // compile-time error | |
A< double > a1; // OK |
Function template parameter
This is probably the cleanest and most universal form the enable_if construct can be used. There are no explicit types for the user to define because the template parameter will be deduced. While the same amount of code is required in this form, the declaration is moved from the function parameter list to the template parameter list.
Personally I like this form the most.
C++
// Only calculate GCD for | |
// type T that is an integer. | |
template< typename T, | |
typename std::enable_if< std::is_integral< T >::value, | |
T >::type*=nullptr > | |
T gcd(T lhs, T rhs) | |
{ | |
// ... | |
} |
Summary
When learning new tools, it is often difficult to see how they are applied. We spent years practicing in math, as we attempted to solve the numerous story problems with each new mathematic abstraction taught to use. Writing code and using libraries is very similar. enable_if is a construct that is best used to help properly define functions that meet concept criteria for a valid implementation. Think of it as a mechanism to help eliminate invalid overload possibilities rather than a tool to allow the selection between different types and your application of this meta-function should become simpler.
A continuation of a series of blog entries that documents the design and implementation process of a library. The library is called, Network Alchemy[^]. Alchemy performs low-level data serialization. It is written in C++ using template meta-programming.
At this point, I was still in the make it work phase of implementation. However, I learned quite a bit from experiencing the progression of design and multiple implementations. So much that I thought it was valuable enough to share.
After the initial creation of the Datum type, it was relatively simple to abstract the design and implement the Bit-Field. object. The next step was to combine the collection of BitField objects into a single group that could be statically-verified as type-safe. This was also relatively simple. Again I just had to model the implementation of the message structure. I called this collection a BitList. Primarily to differentiate it from the std::bitset.
The real trouble appeared when I began the integration of the BitList with the Message in a way that was similar to the Datum. At this point, I started to see the potential this library could provide. Through experience, I have learned that it is important to get the programming interface correct in the initial design. Any mistakes that were made, or code that is not as clean as you would like can be refactored or even re-implemented behind the original interface.
The BitList
My initial approach was straight-forward. As meta-programming was new to me, I looked for opportunities to take advantage of the compiler to verify invariants where ever I could apply them. Therefore, there is a type_check that verifies the number of bits specified by the user does not exceed the capacity of the data type used for storage.
C++
template < typename BaseT, | |
size_t B0, size_t B1=0, size_t B2=0, size_t B3=0, | |
size_t B4=0, size_t B5=0, size_t B6=0, size_t B7=0 | |
> | |
struct BitSet | |
// Are you receiving a compiler Error: | |
// 'Hg::type_check < false >' : base class undefined? | |
// The sum of the provided bits must be <= sizeof(T) in bits | |
: type_check< (B0+B1+B2+B3+B4+B5+B6+B7) | |
<=(sizeof(typename BaseT::value_type)*8)> | |
, public BaseT | |
{... |
I thought the best approach at the time was to store a reference to the primary value, to which all of the BitFields referred. This was an attempt to avoid a mechanism where the child calls the parent for the value then the operation is performed. I was focused on the general usage of the object, and didn’t pay too much attention to the construction of this type. As you can see, the construction of this BitList is quite expensive compared to the amount of information that is encoded in the type.
C++
// Typedef ************************************** | |
typedef typename | |
BaseT::value_type value_type; | |
| |
BitList(value_type &data_field) | |
: m_data(data_field) | |
, m_field_0(GetFieldAddress< 0 >(m_field_0)) | |
, m_field_1(GetFieldAddress< 1 >(m_field_1)) | |
, m_field_2(GetFieldAddress< 2 >(m_field_2)) | |
, m_field_3(GetFieldAddress< 3 >(m_field_3)) | |
, m_field_4(GetFieldAddress< 4 >(m_field_4)) | |
, m_field_5(GetFieldAddress< 5 >(m_field_5)) | |
, m_field_6(GetFieldAddress< 6 >(m_field_6)) | |
, m_field_7(GetFieldAddress< 7 >(m_field_7)) | |
{ | |
m_field_0.attach(m_data); // The assignment in the | |
m_field_1.attach(m_data); // constructor assigns the | |
m_field_2.attach(m_data); // reference of data_field to | |
m_field_3.attach(m_data); // the data member, m_data. | |
m_field_4.attach(m_data); | |
m_field_5.attach(m_data); | |
m_field_6.attach(m_data); | |
m_field_7.attach(m_data); | |
} |
There are two parts to the previous section of code, the initializer list, and the constructor body. The initializer list is used to associate address of the BitField object with the local reference held by the BitList container. This is how the container is able to enumerate over the values in the class. The second part attaches a reference of the internal data field with the child fields.
Because of this twisted setup, the majority of what remains is simple and looks much like the other value classes I have previously shown. The one oddity that remains, is a set of static constants defined to help navigate the set of sub-fields. The code below depends on the knowledge of the size and relative offset for each value.
C++
static const size_t k_size_0 = B0; | |
static const size_t k_offset_0 = 0; | |
| |
static const size_t k_size_1 = B1; | |
static const size_t k_offset_1 = value_if< (B1>0), size_t, k_size_0, 0 >::value; | |
| |
static const size_t k_size_2 = B2; | |
static const size_t k_offset_2 = value_if< (B2>0 ), size_t, | |
k_offset_1 + k_size_1, | |
0>::value; | |
static const size_t k_size_3 = B3; | |
static const size_t k_offset_3 = value_if< (B3>0 ), size_t, | |
k_offset_2 + k_size_2, | |
0>::value; | |
// ... continue through 7 |
Those definitions allow the actual value types fields to be defined with the code below:
C++
value_type &m_data; | |
| |
Bit_field< k_offset_0, B0, value_type> &m_field_0; | |
Bit_field< k_offset_1, B1, value_type> &m_field_1; | |
Bit_field< k_offset_2, B2, value_type> &m_field_2; | |
Bit_field< k_offset_3, B3, value_type> &m_field_3; | |
Bit_field< k_offset_4, B4, value_type> &m_field_4; | |
Bit_field< k_offset_5, B5, value_type> &m_field_5; | |
Bit_field< k_offset_6, B6, value_type> &m_field_6; | |
Bit_field< k_offset_7, B7, value_type> &m_field_7; |
Unfortunately with this design, there will always be eight sub-fields per BitList object, regardless of the actual number of bit-fields that are used. Imagine my surprise when shortly after I released this into the wild, I had requests to support 32 bit-fields per Bitlist. At that point I started to think of ways that I could eliminate all of these unused references. Unfortunately, I was not able to implement my ideas until the second version of this type. So those ideas will have to wait.
Euphamism
To organize the Hg::BitList similarly to the message required an outer container to be defined for the user type. I am not going to show all of the details because they are not that interesting. Also, the current implementation for this feature in Alchemy barely resembles this concept at all. Here is a high-level overview of it’s original structure.
Essentially, the MACRO below is a euphemism for the morass of partially defined parameterized errors waiting to be compiled.
C++
// MACRO declaration of a BitList | |
HG_BEGIN_BIT_LIST(uint32_t, info) | |
HG_BIT_FIELD(0, 4, first) | |
HG_BIT_FIELD(1, 4, second) | |
HG_BIT_FIELD(2, 4, third) | |
HG_BIT_FIELD(3, 4, fourth) | |
HG_BIT_FIELD(4, 4, fifth) | |
HG_BIT_FIELD(5, 4, sixth) | |
HG_BIT_FIELD(6, 4, seventh) | |
HG_BIT_FIELD(7, 4, eighth) | |
HG_END_BIT_LIST |
The name info defines a new BitList type the user will place in the type-list definition that defines the overall message format.
In the end, I spent much more time on this section of code that I am comfortable admitting. So let me just show you a few snippets of what the MACRO definition hides and move away from this.
C++
// ... | |
// The header starts the declaration of a new | |
// container type that becomes the BitList. | |
struct C \ | |
: public Base_bit_list \ | |
{ \ | |
typedef C this_type; \ | |
typedef T value_type; \ | |
typedef Bit_field<0,0,value_type> nil_bits_t;\ | |
\ | |
enum { k_offset_0 = 0 }; \ | |
\ | |
template < typename IndexT, \ | |
typename BitT> \ | |
BitT& GetField(const BitT &) \ | |
{ return GetFieldData(BitT()); } \ | |
\ | |
nil_bits_t& GetFieldData(const nil_bits_t&) \ | |
{ \ | |
static nil_bits_t nil_bits; \ | |
return nil_bits; \ | |
} |
For each field that is defined, a collection of definitions is created by the MACRO that is similar to this:
C++
typedef FieldIndex< 2, this_type,4> idx_2; | |
typedef Bit_field < k_offset_2, 4, value_type > third_t; | |
enum { k_offset_3 = k_offset_2 + N }; | |
third_t third; | |
third_t& GetFieldData(const third_t&) | |
{ return P; } |
-The definition above declares a new Hg::BitField type that meets that criteria for the proper index, offset and size of that field. A new instance of that time is defined with the name the user has specified, and a function is provided that returns a reference to that field. The function requires a const reference of an object of the same type as the desired field (I have since realized that pointers are much less expensive than const references and just as effective). Since all of the fields have different indices and offsets there will be no problems with duplicate types.
The type definitions use a well-defined format that can be programmatically indexed. Therefore developing functions to operate over the fields will be possible. However, there is still more work to integrate this type into the Alchemy framework.
Type-deduced definitions
Throughout the development of this project, the template definitions continued to grow longer and more complex. In many cases, they weren’t that difficult to deal with at all. Rather they were tedious and required the parameterized types to be propagated through the depths of the interfaces to which they applied. It didn’t take long for me to recognize that I could wrap all of the complex definitions into parent-type, and reference my types much like the meta-functions I have been creating. The only difference is in this case I truly do want a simpler definition of the type.
Here is what the definition of a Hg::BitSet with 8 fields that each used 4 bits would look like:
C++
Hg::BitSet< uint32_t, 4,4,4,4,4,4,4,4 > info; |
Because the type information is packaged in the convenient message type-list, all of the details required to reconstruct the Hg::BitList definition is still available, even when packaged like this:
C++
template< size_t Idx, | |
typename format_type> | |
struct Format_bitset | |
{ | |
typedef | |
typename Hg::TypeAt < Idx, | |
format_type | |
>::type base_t; | |
| |
typedef Hg::BitSet< base_t, | |
base_t::idx_0::k_size, | |
base_t::idx_1::k_size, | |
base_t::idx_2::k_size, | |
base_t::idx_3::k_size, | |
base_t::idx_4::k_size, | |
base_t::idx_5::k_size, | |
base_t::idx_6::k_size, | |
base_t::idx_7::k_size | |
> type; | |
}; |
The type-list and index make the Hg::BitList much more accessible, considering all of the other utility functions and definitions that have been created to support the fundamental types.
Integrating as a Datum
At first glance this does not appear to be a difficult issue to resolve. The primary issue is we need to make the Hg::BitList compatible with the existing Hg::Datum type. For a basic template, it would already meet that requirement. Through the use of static-polymorphism, a type only needs to contain the same member data and functions for all of the types to be compatible in an algorithm. They are not required to be tied together through inheritance, which is the basis of dynamic-polymorphism.
The difficulty I ran into, was the logic that I had created to programmatically navigate each field of a message were specialized for the Hg::Datum type. To specialize on a second distinct type would cause ripples through the entire API, and cause almost complete duplicate implementations for alternative specialization. This seems to defeat the purpose of templates. So I searched for a solution to bring the two types together.
BitListDatum
The solution I used for this first version was to create a class, Hg::BitListDatum, which derived from both of these classes. Here is the declaration of the type:
C++
template< size_t IdxT, | |
typename format_type | |
> | |
struct BitListDatum | |
: public Hg::Format_bitlist< IdxT, format_type >::type | |
, public Hg::Datum< IdxT, format_type > | |
{ }; |
The purpose of this class is to become a shallow adapter that is compatible with the definitions and types already defined for the Hg::Datum. The only challenge that I ran into was creating a definition that would allow the Hg::BitList type to be returned for the user to interact with, but still be a Hg::Datum. This is what I created:
C++
typedef typename | |
Hg::Datum < Idx, | |
format_type, | |
StoragePolicy, | |
kt_offset | |
> base_type; | |
| |
operator base_type&() | |
{ | |
return *static_cast< base_type *>(this); | |
} | |
operator value_type() const | |
{ | |
return static_cast< const base_type*>(this)->operator value_type(); | |
} |
The base_type operator properly handles the interactions where a reference to the Hg::Datum type is required. In all other cases, the user can interact with the value_type operator that returns access to the child Hg::BitField objects by name.
Summary
After dynamically-sized arrays, the support of bit-fields has been the most tedious feature to implement in Alchemy. In fact, I do not think implementing support for arrays would have gone nearly as smoothly for me if I hadn’t learned the lessons from implementing bit-field support.
Bit-fields are a feature that are not used much. However, they tend to appear quite frequently when dealing with network protocols or data-storage formats. Once you consider that the bit-field feature is not well defined for C and C++, it becomes clear that an alternate solution for providing bit-level access to the data is important. Mask and shift code is tedious and error prone, not to mention difficult to read if you do not see it often. Considering that the simplification of software maintenance is one of the primary goals of Alchemy, providing a feature such as the Hg::BitList is well worth the effort.
This is an entry for the continuing series of blog entries that documents the design and implementation process of a library. This library is called, Network Alchemy[^]. Alchemy performs data serialization and it is written in C++.
After I had proven to myself that serializing data with a template meta-program was feasible, I started to research what features would be required to make this a useful library. After the fundamental data types, I noticed that sub-byte access of bits appeared quite often in network packet formats, bit-fields. I have also worked in my share of code that implemented these packet formats using the bit-field feature in C/C++.
I decided support for accessing values at the bit-level needed to be a feature of Alchemy. I will explain why, as well as show my first attempt to make this work.
Bit-fields with C++
Bit-fields are like that questionable plate of left-overs in your fridge, yet you choose to eat it anyway. Personally, I avoid both.
In case you are not familiar with bit-fields, here is a brief example:
C++
struct Bits | |
{ | |
char isSet:1; | |
char type:3; | |
char flags:4; | |
}; | |
| |
// This allows these three fields to be packed into the | |
// single char and accessed with the field names. |
The compiler will automatically apply the appropriate mask to the data field to return the value of the named bit-field. This is very convenient. However, there is a catch; the original C specification left the implementation underneath undefined for the compiler implementer to decide. C++ then inherited the same rules. The reason this may be an issue is the bit-fields are not guaranteed to be packed in the order and location that we define them. Therefore, when they are serialized, they will not be correct according to your format specification.
Basically, bit-fields are not portable. Therefore, they should be avoided in code that is intended to be portable, or produces data that should be portable.
Hg::BitField
There is not much logic that is required to extract the correct bits defined in a structure similar to bit-fields. I had just finished an implementation of message fields that act like regular types. My plan was to attempt use the same approach with the Hg::BitField, to allow the user to access each field with a specific variable name. If that did not work, my fallback plan was to simply convert the variable-like syntax to use a function instead.
Masking Bits
As I mentioned earlier, the logic to mask bits out of an integer is just a few lines of code. Let's assume we have a pre-defined mask and we want to change the value of the bit the mask applies to. Here is the code:
C++
void BitField::set_masked_value(const uint32_t &rhs) | |
{ | |
// Member data defined for this bit-field instance. | |
// const uint32_t k_mask = 0x0000FF00; | |
// const uint32_t k_offset = 8; | |
| |
// Mask off the bits we are about to set, | |
// by inverting the mask, and leaving all | |
// of the other bits alone. | |
m_value &= ~k_mask; | |
| |
// Shift the new value by the appropriate offset, | |
// and combine that value with the mask. | |
// This leaves two values with all of the bits | |
// mutually exclusive. Or them together to set the value. | |
m_value |= k_mask & (rhs << k_offset ); | |
} |
To go in the opposite direction is a bit simpler with only one line of code:
C++
size_t BitField::mask_value() | |
{ | |
return (m_value & k_mask) >> k_offset; | |
} |
Calculate Mask and Offset
Hopefully you have seen logic like this before. It may even have been tucked away in a MACRO or something. How do we calculate the mask?
- Take the number of bits in the value, and calculate: 2^n-1
- Determine the starting position of the mask in the value, this becomes the offset.
- Shift the value calculated in step one to the left by the offset.
At run-time we could calculate the mask on-the-fly with this code snippet:
C++
// Where: | |
// n is the number of bits in the mask | |
// start_pos is the index of the first mask bit. | |
uint32_t bits = std::pow(2, n) - 1; | |
uint32_t offset = start_pos; | |
uint32_t mask = bits << offset ; |
Convert to compile-time
The only part of the expression above that currently requires run-time processing is the std::pow() function. More than likely you have already seen a template meta-program implementation of this call, if not at least a recursive implementation. Here is the implementation that I use:
C++
// T is used to define the type of variable. | |
// An instance of T is immediately created to hold var. | |
// Finally the exponent. | |
template< typename T, T var, unsigned char exp > | |
struct pow | |
{ | |
// This expression will take the current var and | |
// multiply it by the remainder of the calculation. | |
// Create a recursive instance with exp - 1. | |
static const T value = var * pow< T, var, exp-1 >::value; | |
}; |
C++
template< typename T, T var > | |
struct pow< T , var, 1 > | |
{ | |
static const T value = var; | |
}; |
C++
template< typename T, T var > | |
struct pow< T , var, 0 > | |
{ | |
static const T value = 1; | |
}; |
The mask expression
Now it is possible to define a constant at compile-time that represents the value of the mask. Two values will need to be passed into the definition of the Hg::BitField template declaration, 1) the size of the field, 2) the offset.
C++
template< size_t OffsetT, | |
size_t CountT, | |
class T = uint8_t> | |
struct BitField | |
{ | |
static const T k_offset = OffsetT; | |
static const T k_size = CountT; | |
| |
// The BitField Mask can be described with this formula: | |
// | |
// Mask = (2 ^ (number of bits))-1 << shifted to the left | |
// by offset bits. | |
// | |
static const T k_mask = | |
T( ((Hg::pow< size_t, 2, k_size>::value)-1) << k_offset ); | |
| |
/// ... |
Hg::BitField declaration
This is the point where I need to front-load my explanation with an excuse because it appears so obvious to me now. However, in the experimentation phase, it is most important to even find a working solution. I subscribe to the mantra:
Make It Work, Make It Right, Make it Fast
This sage advice has been part of the Unix Way for many years, and more recently attributed to Kent Beck with respect to Test-Driven Development. This is the end of the excuse. Spoiler alert, I reworked this class when I reached the benchmark phase and witnessed it's abysmal performance. Hey, It Worked Right, there was no reason to revisit it until I discovered it was an issue.
The initial idea was to create a collector object called a Hg::BitSet, and this would contain the collection of Hg::BitField instances, and also store the actual data buffer. The bit-field objects would only contain a pointer to the value in the bit-set. Originally it was a reference, but I reached a limitation where the Hg::BitField had to be default constructable, and thus the reference initialized to a default value.
C++
// ... | |
BitField() : mp_value(0) { } | |
explicit BitField(T& value) : mp_value(&value) { } | |
void Attach(T& storage) { mp_value = &storage; } | |
| |
operator T() | |
{ return mp_value | |
? mask_value() | |
: 0; | |
} | |
| |
T operator=(const T& rhs) | |
{ if (!mp_value) return 0; | |
| |
*mp_value &= ~k_mask; | |
*mp_value |= k_mask | |
& (rhs << k_offset); | |
return mask_value(); | |
} | |
private: | |
T* mp_value; | |
| |
T mask_value() | |
{ return (*mp_value & k_mask) >> k_offset;} | |
}; |
That's it!
Summary
I am trying to create slightly shorter entries so they can be digested more quickly, and I will be able to update more frequently. The unintended side-effect is that it has also allowed me to focus a bit better.
This entry described the intended purpose and design goals of the Hg::BitField class. In my next Alchemy entry I will show how I integrated the bit-field instance into its container. Then I will describe the hurdles that I started to encounter as my data types became more complex.

Recent Comments