| « Alchemy: Nested Types | Coupling and Cohesion » |
A continuation of a series of blog entries that documents the design and implementation process of a library. The library is called, Network Alchemy[^]. Alchemy performs low-level data serialization with compile-time reflection. It is written in C++ using template meta-programming.
With my first attempt at creating Alchemy, I created an object that emulated the behavior of bit-fields, yet still resulted in a packed-bit format that was ABI compatible for portable wire transfer protocols. You can read about my design and development experiences regarding the first attempt here Alchemy: BitLists Mk1[^].
My first attempt truly was the epitome of Make it work. Because I didn't even know if what I was attempting was possible. After I released it, I quickly received feedback regarding defects, additional feature requests, and even reported problems with it's poor performance. This pass represents the Make it right phase.
Feedback
Feedback is an important aspect for any software development project that has any value, and would like to continue to provide value. Feedback appears in many types of formats including:
- Bug Reports
- Feature Requests
- Usability
- Performance Reports
- Resource Usage
I realized there were limitations with the first implementation of the BitLists in Alchemy. However, I had created a simple proof-of-concept implementation for version 1, and I needed to finish the serialization and reflection features for the library to provide any value at all.
Imagine my surprise when I received the first requests to expand the capabilities of the BitLists from supporting 8 sub-fields to 32. This was already the most expensive structure as far as size in the library, and expanding its bit-field support to 32 quadrupled the size. Therefore, I knew I would have to revisit the design and implementation of this feature rather quickly.
Re-engineering the BitList
My primary concern with the first implementation of BitList was all of the predefined data fields that it contained. For each possible bit-field managed by the BitList, there was an instance of that variable in the object; whether that field was required or not. The primary reason, all of this work is occurring at compile-time. My initial choices appeared to be:
- Predeclare all of the fields up-front
- Create a different implementation for each BitList length
I often mull over projects in my head while I'm driving, walking and during other idle situations. It didn't take long for me to realize that I had already solved this problem of variable field length in other contexts of Alchemy. I solved it using list objects, just like the TypeList.
With the TypeList, I still only had a single implementation that reserves a slot for up to 32 fields. However, the use of code generatng MACROs and default template parameters allowed me to make this solution transparent to the user. My situation with the BitList is slightly different than the TypeList; I did have an idea to account for this difference.
BTW, if you are wondering why a list-based approach did not occur to me earlier, I had originally called this object a BitSet. I changed the name because of this new approach.
The new approach
My new approach would be to create a host, or head, list object that managed all of the external interfaces and details. Internally, I would build up the list one node at a time until the desired number of entries were defined within the BitList itself. The difference between this BitList and the TypeList is the TypeList does not contain any data or variables that can be referenced by the user. The BitList on the other hand, is an object that is fully defined at compile-time and performs real work at run-time.
The final structure is an embedded linked-list. Similar to the TypeList, each node contains a way to reference the next node in the list. This could possibly become a problem that would impede performance for a run-time based solution. However, once the compiler processes this structure, the code will perform as if it is a flattened array.
I estimated the modifications to be relatively benign to all of the objects outside of the new BitList because it was not dependent on any external objects. Moreover, the meta-functions that I created to calculate the type, size, and offsets of the message fields were generic templates that would recognize the new BitList as the previous BitSet.
The implementation
Modifying the code to use this new format was not terribly difficult. I did struggle with the recursive nature of the algorithm to be able to acheive the same results as the original BitSet. The primary issue that I encountered was how to correctly terminate the list. I would end up with one too-many sub-fields, or the bit-count would not be correct.
This is a situation where one can truly experience the value of having a strong collection of unit-tests written for an object. Very few of my tests required any type of adjustment, and I could quickly tell if my refactoring efforts made the system at least as good as it was before, or worse.
Let's take a brief look at the internals of this implementation.
The BitList host
Similar to my first attempt, I created a base class to root the variable to hold the data and basic contruction logic for these fields. This type also helps determine when the end of the list has been reach. However, this class cannot be the sole terminator as I will demonstrate momentarily.
C++
template< typename T, | |
typename FieldsT >; | |
struct BasicBitList | |
: public bitfield_trait | |
{ | |
typedef BitField< 0, 0, value_type >; nil_bits_t; | |
| |
protected: | |
value_type *m_pData; | |
value_type temp_data; | |
| |
// Can only be instantiated by a derived class. | |
BasicBitList() | |
: m_pData(&temp_data) | |
, temp_data(0) | |
{ } | |
| |
BasicBitList(value_type &data_field) | |
: temp_data(0) | |
{ | |
m_pData = &data_field; | |
} | |
}; |
One more thing I would like to point out that never sat well with me, were the two data fields that I defined. The first is a pointer called, m_pData, which actually points to the real storage location for the bit-field data. This pointer is then passed into each bit-field node to allow the nodes to all reference the same piece of data.
The second defined value is called, temp_data, and acts as a place-holder for an uninitialized BitList. This allows the constructor to always assign the field, m_pData, to a valid memory location. It also allows the use of references in the bit-field node objects, which then avoids the need to check for NULL pointers. Still, this part of my implementation always felt like slapping a band-aid on a symptom, rather than solving the actual problem. I am able to eventually remove this band-aid, but not until my third iteration of the BitList.
Let's move from the base class to the top-level host for the BitList, BitFieldList. This first section of logic shows the declaration of the class, common typedefs and constants. This is the class that acts as the head; of the linked-list structure. I am able to make all of the activity resolve itself at compile-time by deriving from a BitFieldNode, rather than declaring the BitFieldNode as an actual data member of this class.
The parameterized type, RootT, accepts the BasicBitList shown previously. This is passed through each BitFieldNode in the linked list until the terminator. This allows each BitFieldNode to have access to the same member data that all of the BitFieldNodes share.
C++
template< typename RootT, | |
typename SeqT> | |
struct BitFieldList | |
: public BitFieldNode< RootT, 0, 0, SeqT > | |
{ | |
typedef typename | |
RootT::value_type value_type; | |
typedef typename | |
BitFieldNode< RootT, 0, 0, SeqT > base_type; | |
| |
// Constants ********************************* | |
static | |
const size_t k_size = sizeof(value_type); |
The only other definitions for this class are the set of constructors that initiate the cascading initialization process that occurs as each derived BitFieldNode is initialized.
C++
// Default constructor | |
BitFieldList() | |
: base_type() | |
{ | |
RootT::m_data = 0; | |
} | |
| |
// Const Value constructor, | |
// Typically used for temporary instances. | |
// This call will use internal memory to store values. | |
BitFieldList(const value_type &data_field) | |
: base_type() | |
{ | |
RootT::value(data_field); | |
} | |
| |
// Value constructor. | |
BitFieldList(value_type &data_field) | |
: base_type(data_field) | |
{ } |
The BitFieldNode
This class is the innovation of the second iteration of the BitList object. Rather than storing a fixed collection of these types in the container object, a compile-time linked-list is created by deriving the current node from the next node in the sequence. This would most likely cause a very inefficient implementation if it were a solution based on dynamic polymorphism. However, I found through analysis of the compiled code that the overall structure is flattened out by the compiler, and becomes as efficient as if they were all declared as peers in the same container.
C++
template< typename RootT, | |
size_t IndexT, | |
size_t OffsetT, | |
typename SeqT> | |
struct BitFieldNode | |
: BitFieldNode< RootT, | |
IndexT+1, | |
OffsetT+Front< SeqT >::value, | |
typename GetTail< SeqT >::type | |
> | |
{ | |
// Typedef ************************************** | |
typedef typename | |
GetTail< SeqT >::type tail_type; | |
| |
typedef typename | |
BitFieldNode < RootT, | |
IndexT+1, | |
OffsetT+Front< SeqT >::value, | |
tail_type | |
> base_type; | |
| |
typedef typename | |
RootT::value_type value_type; |
While the BitFieldNode derives from the next node in the sequence, this instance defines a BitField object to manage the mask and shift operations to operate on the appropriate bits in the common storage data. The BitField object remains unchanged from the version I used in the first BitList implementation. It is also the same version that I have previously written about.
The salient detail to recognize in the constructors, is the base class is first initialized, then the local BitField is initialized. Remember the base type will eventually reach the BasicBitList that houses and initializes the actual storage data for this entire structure. Therefore on the return pass, each BitFieldNode is initialized with valid data starting from the tail node and finishing at the head.
C++
// Default Constructor. | |
BitFieldNode() | |
: base_type() | |
, m_field( RootT::GetFieldAddress(m_field) ) | |
{ | |
m_field.attach((value_type*)&rhs.m_field); | |
} | |
| |
// Value constructor | |
BitFieldNode(value_type &data_field) | |
: base_type(data_field) | |
, m_field(GetFieldAddress< IndexT >(m_field)) | |
{ | |
// assigns the reference of data_field | |
// to the data member, m_data. | |
m_field.attach(&data_field); | |
} | |
| |
private: | |
BitField< OffsetT, | |
Front< SeqT >;::value, | |
value_type > &m_field; | |
}; |
The BitFieldNode Terminator
At the end of the set of nodes in the linked-list, is a specialization of the BitFieldNode that derives from the passed in BasicBitList rather than the next node in the chain. I cannot recall the exact troubles that I ran into trying to find the correct set of definitions to properly terminate this list. I do remember that I continued to switch back-and-forth between having an incorrect number of sub-nodes in the list and an incorrect offset for each field.
The code below is the final correct solution at which I arrived. The first block contains the declaration and the constructors.
C++
template< typename RootT, | |
size_t IndexT, | |
size_t OffsetT | |
> | |
struct BitFieldNode< RootT, IndexT, OffsetT, MT> | |
: public RootT | |
{ | |
// Typedefs ******************************* | |
typedef typename | |
RootT::value_type value_type; | |
| |
BitFieldNode(const BitFieldNode &rhs) | |
: RootT(rhs) | |
{ } | |
| |
BitFieldNode(value_type &data_field) | |
: RootT(data_field) | |
{ } |
The function below is something that I carried over from the first implementation as well. It allows internal references to the actual BitField objects to be queried by index. The basic mechanism that allows the compile-time reflection to occur over this type.
C++
// A parameterized method that allows the | |
// BitList heirarchy to pragmatically access | |
// the different bit-fields defined in the list | |
// without knowledge of the name of the field. | |
template< size_t Idx, | |
typename field_t > | |
field_t& GetFieldAddress(const field_t&) | |
{ | |
typedef FieldIndex< Idx, RootT, field_t::k_size> field_index_t; | |
| |
// Calls a template member function "GetField" | |
// found in the base class "RootT". | |
// | |
// The static_cast from this to a type "RootT" | |
// is required to give a hint to the compiler where | |
// to look for the "GetField" function. | |
return | |
static_cast< RootT* >(this)->template | |
GetField< field_index_t >(field_t()); | |
} |
The results
Overall I was pleased with this solution, especially compared to my first-pass attempt. This version felt more like a Make it Right type of solution, rather than the starting phase of Make it Work. A few portions of the implementation still didn't sit right with me. For example, an extra dead-weight temporary to ensure that I never dereferenced a NULL pointer.
There is one other source of pain that I experienced with this implementation. This is a result of the deep-derivation that I used to create the compile-time linked list. When I was working through the defects and creating new tests, I spent a fair amount of time in the debugger inspecting the contents of BitList variables and the data found in each node. Unfortunately, this data structure was not very convenient to troubleshoot.
Here are two snapshots of what the following BitList definition looks like when expanded in the Visual Studio debugger:
C++
HG_BEGIN_BITLIST (uint32_t, mixed_set) | |
HG_BIT_FIELD (0, first, 5) | |
HG_BIT_FIELD (1, second, 4) | |
HG_BIT_FIELD (2, third, 3) | |
HG_BIT_FIELD (3, fourth, 2) | |
HG_BIT_FIELD (4, fifth, 1) | |
HG_BIT_FIELD (5, sixth, 16) | |
HG_BIT_FIELD (6, seventh, 1) | |
HG_END_BITLIST |
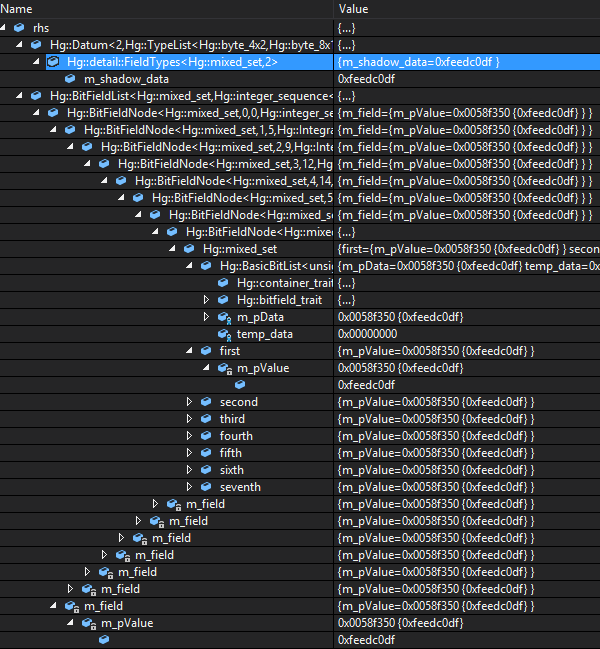
It is easy to see that the value stored in the entire BitList is 0xfeedcodf. However, that is also the value displayed when the bit-fields are expanded. Therefore the debug data viewer provides much less value than I had hoped it would.
This view is an expanded view of just the type names for each field in the derived BitFieldNode chain.
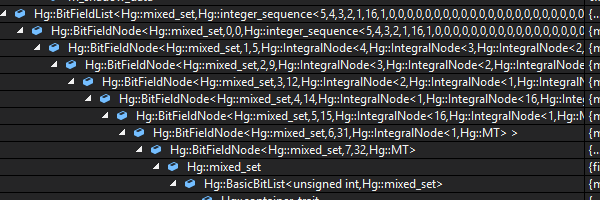
Needless to say this irritated me enough that I eventually created some custom Visual Studio visualizers that I added to Alchemy to correct this inconvenience.
Summary
The usage of the BitList changed from the point-of-view of the final user. However, I was much more satisfied with this solution than the original solution. This solution expands gracefully to any length the user defines (within reason). The amount of space required for each field is reduced to only require space if a BitFieldNode is defined. Therefore, only as much space is allocated as is required for the data structure.
Unfortunately, this data type still remains the most expensive data type that is supported by Alchemy. One pointer is added for each BitField specified in the BitList. This amounts to 4*32 = 128 bytes on a 32-bit system for a BitList with 32 1-bit flags. This is in addition to the other overhead incurred for each type.
I was pushing off my worries about performance as I was not ready yet to write the benchmark tests. I will admit I was concerned, and as you will soon find out, I discovered some very compelling reasons to make my third attempt at implementing the BitList.

Recent Comments