Deprecated: Function create_function() is deprecated in /home2/codeopb4/public_html/plugins/code_highlight_plugin/highlighters/geshi.php on line 4736
Pointers are one of fundamental topics related to programming that can be quite confusing until you develop your own personal intuition for what they are and how they work. Passing on this intuition is also a difficult task, because once the more experienced developer finally understands pointers, they seem to entirely forget what was so confusing in the first place.
I will attempt to pass on the intuition I have developed for using pointers in C and C++. The metaphors and explanations that I use are based on a number of attempts to help beginners struggling with concepts. Each of whom now have a better understanding of these confounding constructs. Even if you are completely comfortable with pointers, maybe I can possibly give you another approach to help better explain these fundamental tools to others.
This post will introduce pointers and the syntax for interacting with them. I will write a follow-up post that addresses more complex things that are done with pointers, such as creating data structures and using function-pointers.
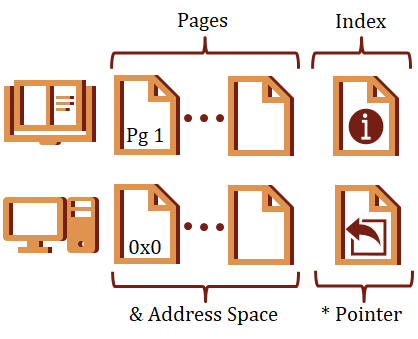
Analogy: Computer as a Book
I want to start with an analogy. Think of your program as a book. The pages are like memory addresses, and the content on each page is the data.
A pointer in this context would be an entry in the index. The name of the entry is similar to the name of your pointer. This entry takes up space in the book, but the entry itself does not contain any data. Instead, it contains a page-number (address) where you can actually find the data related to this index entry.
You cannot access the data the index refers to directly from the index itself. Rather, you must first dereference the index (pointer) by navigating to the page (address) indicated for the entry.
Data
With computers, there are two ways to reference data, directly and indirectly.
Direct references are to variables that refer to data that is directly associated with the storage location for the variable. These types of variables have been statically allocated, which means they are local variables allocated on the stack, global variables, or variables that have been declared with the static qualifier. To keep things simple, I will only use local variables in the code examples.
Addresses
Indirect references do not have storage associated with the data to be accessed. Instead, we have a variable that points to the storage location. The storage location is a memory address on the computer. Essentially, a pointer is a variable that stores a memory address. Pointers, References, and even Arrays are all forms of indirect data access. This post focuses on the Pointer.
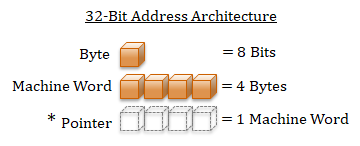
A computer address requires a value that is the size of a machine-word. The machine-word size can be deduced by the target machine's architecture. For example, a 32-bit architecture has a word-size of 32-bits. Virtually all modern architectures use an 8-bit byte. Therefore, a 32-bit architecture has a machine-word size of 4 bytes. Since a pointer is a variable that holds an address, a pointer will be the same size as the computer's machine-word.
Pointer Initialization
A pointer must be initialized before it can be dereferenced. Dereferencing an uninitialized pointer is considered undefined behavior, which basically means your program won't work. There are two things that you can use to initialize a pointer, 1) a valid address in your program, 2) NULL or 0. NULL is defined in both C and C++, but it is generally advised to not use NULL because it is not defined portably across different systems. Instead, you should use the value 0.
One note of caution, Operating systems typically do not map data at the address 0x0. However, 0x0 may be a valid address on some resource constrained bare-metal systems. Therefore, take the time to learn the details for each system on which your programs will execute.
A new literal value for pointers was added to C++ 11 called, nullptr. This is a safe and portable value that can be assigned to a pointer to indicate that it does not reference anything valid. If you are using newer versions of C++, this is the recommended value to assign to empty pointers..
Pointer Notation
Let's review the different types of syntax that can be used to interact with pointers. The operations include the ability to take the address-of a data location, dereference a pointer to its data location, and even accessing members of complex data structures.
Address-Of Operator &
The & becomes the address-of operator when placed in front of a variable. Use this operation to create a pointer to variable. This is a fundamental operation that is used to assign indirect storage to pointers and pass local variables to functions that expect pointers.
C++
char buffer[] = "2147483647 is 2^31 - 1"; | |
char* p_end = 0; | |
| |
// Convert the text string to a number. | |
// The last character parsed is returned in p_end. | |
long value = strtol(buffer, &p_end, 10); | |
| |
long p_long* = &value; // The address where value is located | |
// is assigned to the pointer |
Indirection Operator *
The * is the dereference operator when placed in front of a pointer. This is how to access the underlying data referenced by the pointer. You must dereference a pointer if you want to access the data for both reading and writing to its indirect storage location.
C++
char* strcpy(char* dest, const char* src) | |
{ | |
// Copy each character from src into dest | |
// until the terminating NULL is found. | |
char* cur = dest; | |
// Dereference src to read its value | |
while (*src != 0) | |
{ | |
// Dereference src to read its value for assignment | |
// to the current location of the dereferenced cur. | |
*cur = *src; | |
// Advance the location pointed to by | |
// both of these pointers, i.e. next character. | |
cur++; | |
src++; | |
} | |
| |
// Copy the final NULL termination. | |
*cur = *src; | |
| |
return dest; | |
} |
Member Access Operator ->
Structs and classes collect a set of member data and functions into a single construct. If you have a pointer to an object and want to access one of its members, you will have to dereference the object pointer before you can access the members.
C++
struct Entry | |
{ | |
int key; | |
int value; | |
}; | |
| |
Entry* p_entry = new Entry; | |
(*p_entry).key = 1; | |
(*p_entry).value = 100; |
This syntax is a bit cumbersome. There is a member access operator that can indirectly reference their members ->.
C++
Entry* p_entry = new Entry; | |
p_entry->key = 1; | |
p_entry->value = 100; |
Subscript Operator [ ]
Arrays provide a convenient method to refer multiple data locations through a single variable. Arrays are pointers dressed up in disguise. The same notation used to access an index in an array can be used with pointers to access an element offset from the base address of the pointer.
C++
// Allocate a block of 10 integers | |
int* p_ints = new int[10]; | |
| |
// Remember, zero-based indexing in C and C++ | |
p_ints[0] = 1; // Assign 1 to the first element, which is | |
*p_ints = 1; // equivalent to this operation | |
| |
p_ints[1] = 2; // Assign 2 to the second element | |
p_ints[9] = 10; // Assign 10 to the tenth element |
Notice how the pointer indirection is automatically handled when the subscript operator is used. To be clear, an array and a pointer accessed with the subscript operator are two different things. The array is located at the same address as the variable's storage. On the other hand, the pointer contains an indirect address to the storage. When the subscript operation is used on the pointer, its address is first dereferenced before the value is indexed. You can test this with the sizeof operator to report these size of the variable in question.
C++
int array_ints[10]; | |
int* p_ints = new int[10]; | |
| |
size_t array_size = sizeof(array_ints); // 10 * size of int (4) = 40 | |
size_t pointer_size = sizeof(p_ints); // word size = 4 |
Although the array has storage associated with its variable, if the array is used directly without a dereference operation, the address of the array is returned. In essence, the array is a dressed up pointer. However, you cannot assign a new pointer to an array variable. When you pass an array as an input parameter to a function expecting a pointer, it is implicitly converted to a pointer. This is also true if you attempt to declare a function with a parameter that is an array. You can learn more about that from a previously written post on Type Decay[^].
Pointers to Pointers
Sometimes it is useful to hold a pointer to a pointer. If you wanted to declare a variable to hold a pointer to a pointer, it would look like this:
C++
char value = 0; | |
char* p_value = &value; | |
// Declare a pointer to a char pointer | |
char** pp_value = &p_value; | |
| |
// A double indirection is required to read the | |
// actual value stored at the final address. | |
char data = **pp_value; |
There two reasons that I can think of to use multiple levels of indirection. The first is to make call-by-reference functions calls with pointer variables. Call parameters for functions in C can be either call-by-value or call-by-reference. Call-by-value places the value of the variable on the call stack, whereas call-by-reference places the address of the variable on the call stack. You use call-by-reference when the called function will modify the call parameter passed to the function. In the case of the strtol example, a pointer to the first character after parsed number is returned.
Call-by-reference is especially valuable when you have more than one value that you would like to return from a function.
Here is an example of double-indirection by a function that allocates a new buffer to copy the contents of a string. The second level of indirection is required so the caller can receive the updated value of the pointer, which points to the newly allocated buffer.
C++
// Allocate a buffer to hold a copy of the input string. | |
// The number of bytes allocated | |
size_t CopyString(const char* input, char** output) | |
{ | |
size_t len = strlen(input) + 1; | |
| |
*output = new char[len]; | |
strncpy(*output, input, len); | |
| |
return len; | |
} |
The other reason is to dynamically create an array of pointers. For that matter, even a statically allocated array of pointers has double indirection. An array of pointers could be used as a container for other dynamically allocated variables, or a function-pointer table. I will discuss function-pointers in the follow-up post to this article.
Pointer Arithmetic
The final concept that I want to introduce in this post is pointer arithmetic. It is commonly used. It is also easy to mess up if you aren't paying attention. I think it is important to walk through this concept to help you from being surprised when you work with different pointer types in this context. The pointer type supports basic addition and subtraction, which also includes the increment ++ and decrement -- operations.
Using the subscript notation is a simply a different form of performing pointer arithmetic, followed with indirectly referencing the data at the specified index. A pointer is an indirect reference to a specific type. Whether it is to one of the fundamental types, an object or even another pointer, this referenced type has a size associated with it. Adding one to a pointer will increase its value by the size of its referenced type. Similarly, subtracting one from a pointer will reduce its value by that same size. Therefore, the subscript operator intrinsically performs the pointer arithmetic to identify the location of the index from the base pointer.
C++
int* buffer = new int[10]; | |
// ... Populate the contents of the array | |
| |
// These two statements are equivalent | |
buffer[4] = 101; | |
*(buffer+4) = 101; |
Be cautious when performing pointer arithmetic, because if you attempt to calculate an offset with the wrong type, the wrong type-size may be used in your calculation. This is most likely to happen when you are converting data between types, such as reading a message from network communication.
Finally, you cannot perform pointer arithmetic on a void*. This pointer type is an intermediate type that must be cast to another type before it can be dereferenced or indexed.
Deduce Its Type
When you are wading through a morass of pointer code, I find it useful to deduce the type for variables with lots of indirection. Especially pointer logic that is iterating through the elements of a buffer.
We will deconstruct the types from this snippet of code:
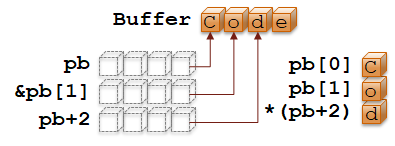
C++
char Buffer[] = "Code"; // Statically allocated char array | |
char* pb = Buffer; // char* points to first buffer char | |
char b0 = pb[0]; // Dereference char* becomes char, 'C' | |
| |
char b1 = pb[1]; // Dereference char* becomes char, 'o' | |
char* pb1 = &b1; // then take address results in a pointer. | |
// Equivalent to this: &pb[1] | |
| |
char* pb2 = pb+2; // Add char slots from base pointer, | |
// results in a new pointer | |
char b2 = *pb2; // Dereference points to 'd' | |
// Equivalent to this: *(pb+2) |
Let's do one more. This time a bit more complex:
C++
// Create two strings, | |
char* pHello = new char[6]; // This one is dynamically allocated | |
strncpy(pHello, "Hello", 6); | |
| |
char pWorld[] = "World"; // This one is statically allocated | |
| |
char** ppStrings = new char*[2]; // Allocate an array of char* | |
// This is a pointer to a char pointer | |
ppStrings[0] = pHello; // Let's associate pHello with the first index. | |
// We dereference the first pointer | |
// This gives us a char* pointer. | |
// Now we can assign pHello | |
ppStrings[1] = pWorld; // The same applies to the second string. | |
| |
// For cleanup, must delete 2 allocations | |
delete[] ppStrings; // Be sure to use [] version of delete | |
delete[] pHello; // Same for pHello. | |
// pWorld was not dynamically allocated |
Summary
Pointers are essential to perform many operations in C and C++. Arrays are basically pointers in disguise. The indirect nature of pointers can lead to confusion, and the difference between the size of the pointer and the size of its type can lead to confusion. I showed in this article how you can successfully manipulate pointers by identifying the type of variable you are working with before performing any operations. In the next part, I will tackle some more complex topics related to pointers, which includes data structures and function-pointers.
]]>






