| « The "Little Planet" Effect | Leave the Key Under the Mat » |
I wanted to start writing about secure coding practices as well as more instructive posts related to security topics such as encryption and hacking. You probably already have a conceptual understanding of things like the "stack", "heap" and "program counter". However, it's difficult to have concrete discussions regarding security unless you have a solid grasp on the computer memory model. This post is intended to provide a concrete foundation of the memory model, and my future posts related to security will build on this foundation.
It is easy to take for granted the complexity of computer memory because of the many layers of abstraction that programmers work through today. The same basic memory design has existed for all computers that use a paged memory structure since the early 60's. These are some of the areas where the knowledge of the memory layout plays a crucial role in application portability and embedded resources, program security, code optimization. The diagrams I present will also help you understand where the different activities occur in a program during runtime.
Memory (RAM)
Random Access Memory (RAM) is where the majority of your program will live while it is actively running. As the name indicates any position in your application is capable of being addressed by the hardware. When your program is executed, it will be loaded at some starting address. This address is typically called the Base Address. The value of the base-offset differs from system to system. A technique called, Address Space Layout Randomization (ASLR), loads your program's modules at random address locations to make hacking a bit more difficult.
RAM addresses start at zero and reach whatever limit is imposed by the system on which you are running. However, not every address is accessible by your program; some areas are reserved for the operating system. The hardware and operating system work together to abstract the details for accessing locations in RAM. Therefore, RAM can be thought of as one continuous linear array of bytes. Let this be basic representation of the layout of RAM for this discussion.

All of the sections described below are located in RAM.
Segmentation
Systems that utilized segmented RAM started to appear in the 60's with operating systems written with higher level languages. Originally, segmentation provided many services such as creating the ability address memory address higher than the word size of the processor. For Windows developers, the FAR specifier is a remnant of the limited ability to access addresses on 16-bit Intel chips, such as the 80386.
Now, the primary feature implemented with segmented memory is memory paging (segment) and virtual addressing. I do not want to get into the technical details regarding virtual memory here, but I can revisit that topic in the future. For now, realize that these features allow the system to store and order all of the active resources in the most efficient way possible while hiding the details from the programmer.
From this point on, I will call a memory segment a page. A page is a pre-determined number of bytes that are considered a single group. Memory is most efficiently managed as pages. All of the modern architectures that I have worked with have used a page size of 4Kb (4096 bytes). Why stop there? Because 4097 bytes would have been just too many?!
Now that memory segmentation has been introduced, let's alter the representation of RAM just a bit to simplify the illustrations. This new abstraction will help us visualize the concepts in a more manageable way:
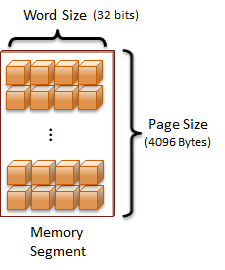
Program structure
The descriptions that I give below are in general terms because there are subtle nuances between the different executable formats defined on each platform. For instance:
- Unix/Linux:
- COFF is an older format
- ELF is the current format
- Mac OS X:
- Mach-O
- Windows:
- NE, derived from DOS formats for 16-bit Windows
- PE, 32-bit Windows
- PE32+, introduced for 64-bit Windows
While the actual file definitions vary between different platforms, executable programs are generally organized with different memory sections as described below.
Program header
There are basically two types of sections to consider when discussing executable file formats: 1) Read-Only segments, 2) Read-Write segments.Why isn't the entire program just made Read-Only, we don't want the program to be changed do we?
The actual file the program is store in is not used directly. The program header directs the loader to the different segments, which are described below.
Read-Only
The Read-Only segments can be loaded into shared memory of the current system. Therefore, space can be saved when multiple instances of the same module are executed.
Read-Write
Each Read-Write segment must be given its own copy relative to the process that uses it. These segments cannot be safely shared between processes unless special care is taken by the developer.
Section header
Each type of program segment is described below. I will indicate whether it is typically a read-only or read-write segment, as well as the role it plays in the execution of the program. Most module formats do not restrict the segment types to a single instance. I will describe some of the possibilities in the relevant sections below.
.text (RO)
Another name used for this segment is the code segment. This is where the sequence of hardware commands are encoded sequentially to command the processor. It is important for this segment to be loaded into a read-only region of the system's RAM to prevent self-modifying code. Self-modifying code is extremely difficult to debug, and it creates a great potential for security vulnerabilities.
It is also important to mention that most systems require memory segments to be marked with the "executable" privilege in order to process the segment as executable instructions.
.rodata (RO)
Some file layouts include a read-only data section to store constants and other read-only data that needs to reference an address by the program. This segment type is found in the ELF format. Again, this segment type is not used in all program file formats.
.data (RW)
The data section contains pre-allocated storage space for all of the global and static variables defined in your program. These values are packed efficiently for the target platform so they can be accessed on the proper memory boundary for the size of the data type. The commands generated in the .text segment reference the values in this segment at a relative offset during run-time. First the address of the segment is found, then the relative offset of the desired variable is accessed as needed.
A program may want to define multiple .data segments to create a simple mechanism to share data between two processes. This is called a shared data section. I have only used this technique in Windows, so I do not know the specifics for its use on other platforms.
The shared segment is loaded into globally accessible system memory. Any process that loads this module will have access to the same variables. If one process changes a value, this will be instantly reflected in all other processes. I have used this mechanism to synchronize unique data among different programs on a single system.
.bss (RW)
The .bss section is unique compared to the other segments. There is only one .bss per module, and it is not actually included in the module. That is because the .bss is the segment where all of the uninitialized data fields of a module are located.
The size required to store the uninitialized fields is all that is required in the definition for the .bss. The initialized fields defined below would be placed in the .bss address space:
C++
int classId; | |
char courseName[32]; | |
std::vector< student > classRoster; | |
| |
// Static member variables and local static variables | |
// will also be allocated in the BSS. |
Runtime Structure
Now that we have defined each of the major types of segments that exist in all modern computer architectures, let's describe how they are structured in a running program. There are three types of memory that are directly referenced by machine instructions.
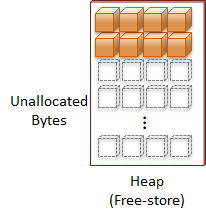
Heap
The Heap is where all dynamically allocated memory is located. Another name for this collection of memory is the Free-Store. The heap is essentially all of the remaining accessible RAM that isn't used by your program modules or isn't reserved for the stack.
Call-Stack
The Stack is a nickname for the Call-Stack. The call-stack is where parameters are passed into functions and storage is allocated for local variables. That is why it is referred to as "creating the variable on the stack". A stack-frame is used to represent each instance of a function call. Each time a function is called, the current function state is recorded at the current location on the stack, and a new stack-frame is pushed onto the stack to track the next function. When a function call returns, the current stack-frame is popped off the stack, and the previous function state is restored to continue execution.
One call-stack is allocated for each thread that is started in the program. In order to efficiently use the available address space on the system, a stack-size is usually defined for each thread's call-stack. Factors that you want to consider when selecting the size of your call-stack is the size of the local variables created in your functions and how deep your function calls execute.
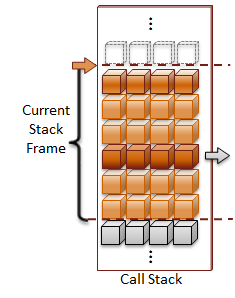
I am going to leave the specific details to how the call-stack is managed for a later post; because call-stack processing is a complex topic that requires an entire post on its own. What is important to understand for now is that function call management and local variable allocations are the primary responsibilities of the call-stack.
System Registers
The hardware registers are memory locations that are actually housed within the CPU. The registers are the same size as the word-size for the CPU. Word has taken on a different meaning over the years with computers. In the context of hardware, word-size always means the bit-width of the processing pipeline of the CPU. For instance, the word-size on a 32-bit processor is 32-bits, and the word-size for a 64-bit processor is 64-bits.
They are crucial to the structure of a computer system. The registers are the CPUs only way to operate upon the values when a command is executed. Values are loaded into the registers from addressable RAM locations via the system bus. If the CPU has an internal memory cache, large chunks of data can be pre-loaded from RAM. This will ensure the data is ready when the CPU is ready to process an instruction. The CPU cache can provide an enormous boost in performance.
Fundamental x86 and AMD64 Registers
The types of registers that are available depend upon the CPU's ISA (Industry Standard Architecture). I am going to briefly introduce the commonly used registers for the x86 ISA, because all three major desktop operating systems (Apple, Linux, Windows) support this platform.
There are eight general purpose registers and the Instruction Pointer, which holds the program counter. The registers are named based upon a purpose that was originally envisioned for each register. There are special operations that are designed for specific registers; such as the Accumulator, EAX, has an efficient opcode to add a byte index specified for it. However, the other registers support these operations as well; only the opcodes are longer general-purpose commands.
| 16-bit | 32-bit | 64-bit | Purpose | |
| AX | EAX | RAX | Accumulator | |
| BX | EBX | RBX | Base index (arrays) | |
| CX | ECX | RCX | Counter (loops) | |
| DX | EDX | RDX | Extends the precision of the accumulator | |
| SI | ESI | RSI | Source Index for string operations | |
| DI | EDI | RDI | Destination Index for string operations | |
| SP | ESP | RSP | Stack Pointer | |
| BP | EBP | RBP | Base Pointer | |
| IP | EIP | RIP | Instruction Pointer | |
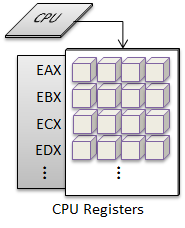
The first four registers of the previous table have additional registers defined to access the low-order and high-order bytes of the 16-bit register. The x86 and AMD64 instruction sets use an 8-bit byte. Here are their names:
| 16-bit | Low Byte | High Byte | ||
| AX | AL | AH | ||
| BX | BL | BH | ||
| CX | CL | CH | ||
| DX | DL | DH |
The stack-pointer typically points to the top of the call stack to indicate the next address to use for parameter passing or local variable allocation. The instruction-pointer points to the address of the current instruction to execute. This address should always be pointing to an address that is found in the .text segment of your program, or the system's libraries.
Interactions
Ignoring restrictions due to permissions, RAM can be addressed as one continuous sequence from the lowest address to the highest address. The system will move segments in-and-out of RAM one page of memory at a time. There are typically regions of the address space that is reserved for the operating system (kernel). If shared memory between processes is allowed on the system, then a region will also be reserved for globally accessible address space.
Your program itself is loaded into available address space. There is no universally common addressing scheme for the layout of the .text segment (executable code), .data segment (variables) and other program segments. However, the layout of the program itself is well-formed according to the system that will execute the program. This allows the system's program loader to navigate the program file and properly load the program into RAM. Jump tables and other internal structures are fixed up to allow the different memory segments to be properly referenced based on their final address.
The diagram below depicts a simplistic view of a single program's elements loaded into memory on a system. The CPU accesses the RAM through the system bus.
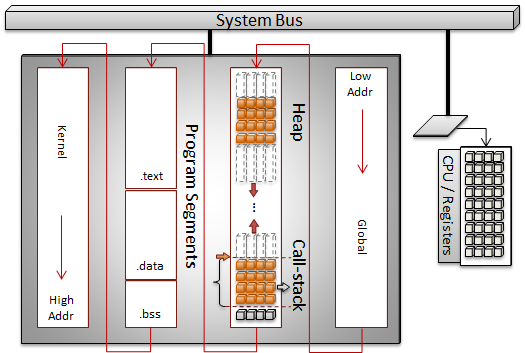
The call-stack and heap are usually situated at opposite ends of the address space and they grow towards each other. If the program allocates too much dynamic memory, or a recursive call continues unbounded the system will run out of address space. For the recursive function call scenario, the stack will have used all of its allotted space and cause a stack-overflow.
The only hard boundaries in this continuous address space is typically at the page-level. Therefore if an operation attempts to access memory across a page boundary a segmentation-fault or segfault will occur. If permissions are set to restrict access to specific pages and a program attempts to access the space, some type of access violation is raised.
Summary
Most programmers do not need to have a deep understanding of a computer's memory architecture in order to complete their jobs. However, having a solid understanding of this memory model can help you make better design decisions and improve your debugging skills. As you move closer to the hardware in your development, it becomes more necessary to truly understand this structure. Finally, there are some tasks that are simply not possible to accomplish (or at least them become extremely difficult) if you do not have a clear picture of the memory structure for computers.
Security is one of the concepts with computer programming where it becomes necessary to have a better understanding of this structure. Even though you may never look at a disassembled program or manually access the registers, it is important to understand how what causes a security vulnerability, as well as the qualities that make a vulnerability exploitable. So with this foundation of memory structure, I will be able to write about secure programming practices and also demonstrate some of the techniques used to exploit these flaws.

Recent Comments